Frequently, we're interested in using sample data to obtain an unbiased estimator of a population variance. We do this by using the sample variance, with the appropriate correction for the degrees of freedom. Similarly, in the context of a linear regression model, we use the sum of the squared OLS residuals, divided by the degrees of freedom, to get an unbiased estimator of the variance of the model's error term.
But what if we want an unbiased estimator of the population standard deviation, rather than the variance?
The first thing that we have to note is that when we say that an estimator is "unbiased", we're saying that the expected value of the estimator (i.e., the mean of the estimator's sampling distribution) equals the true value for the parameter that we're estimating.
The second thing to note is that the expectation operator is a linear operator. This property has some advantages, but also some disadvantages. For example, the expectation of any linear function of a random variable (here, the estimator) is just that function of the expectation. Specifically, if E[X] = μ, and a and b are constants, then E[a + bX] = a + bE[X] = a + bμ. However, in general the expected value of a nonlinear function of a random variable is not simply that function of the expectation. That is, E[g(X)] ≠ g[E(X)] if g(.) is a nonlinear function.
An immediate implication of this is the following. Suppose that we construct the following unbiased estimator of a population variance, σ2:
S2 = [∑(xi - x*)2)] / (n - 1) ,
where x* is the average of the sample values, xi ; i = 1, 2, ...., n.
While E[S2] = σ2, E[S] ≠ σ, because taking the square root is a nonlinear operation.
Similarly, if we have a k-regressor linear regression model,
y = Xβ + ε ; ε ~ [0 , σ2In]
and e is the OLS residual vector, then although the estimator s2 = e'e / (n - k) is unbiased for σ2, once again E[s] ≠ σ.
In other words, taking the square root of an unbiased estimator results in a biased estimator of the square root of the original parameter.
There is a little bit of light at the end of the tunnel. If the nonlinear transformation that we're making is strictly convex, or strictly concave, we can at least put a a sign on the direction of the bias that we introduce by transforming the estimation problem.
Jensen's inequality tells us the following. Suppose that h(.) is a strictly convex function. Then E[h(X)] ≥ h(E[X]). Conversely, if h(.) is strictly concave, then E[h(X)] ≤ h(E[X]).
Now, the square root transformation is strictly concave. This means that in each of the two examples above, we can certainly say that s is a downwards-biased estimator of sigma.
That's great, but it tells us nothing about the magnitude of the bias when we use s to estimate σ. Neither does it tell us how we might modify S (or s) in order to get an estimator that is unbiased for σ.
You won't find these two issues discussed in your typical econometrics textbook, but it's really not difficult to address them properly. To heck with "signing" the bias of s as an estimator of σ, let's get some exact results!
Before we start, there's one really important thing that has to be noted. The unbiasedness of S2 or (s2) as an estimator of σ2 doesn't require that the population follows any particular distribution (such as normal). The population distribution just has to have finite first and second moments, so that σ2 is actually defined. On the other hand, the following results relating to unbiased estimation of σ itself require that we are sampling from a normal population.
With that in mind, let's see what Holzman (1950) had to say about all of this. He provided a really simple proof that E[CnS] = σ, where n is the sample size and the constant, Cn, is defined as:
Cn = {Γ [(n - 1) / 2] [(n - 1) / 2]1/2} / Γ(n /2) .
It follows, trivially, that E[cns] = σ, where:
cn = {Γ [(n - k) / 2] [(n - k) / 2]1/2} / Γ [(n - k + 1) / 2] .
So, both S and s are biased estimators, with biases given by B = (σ / Cn) - σ, and b = (σ /cn) - σ, respectively.
Another way to get to the same result is a follows. Given the assumption of a normal population, the statistics (n - 1) S2 / σ2 and (n - k)s2 / σ2 are each chi-square distributed with (n - 1) and (n - k) degrees of freedom, respectively. The (positive) square root of a chi-square random variable follows what's called a Chi distribution. If you're aware of this, you can then use knowledge of the mean of that distribution to get the results established by Holzman. Of course, the math. that's needed to derive the expression for that mean (if you don't where to look it up) is precisely the same as we've just been through!
Looking at the expressions for the biases of S and s, and their bias-adjusted counterparts, it's pretty clear that the sample size, n, doesn't have to be terribly big before the bias becomes negligible. (Asymptotically, both estimators are weakly consistent for σ. This follows from the consistency of S2 and s2 for σ2, and the application of Slutsky's theorem. So, S and s are asymptotically unbiased for σ.)
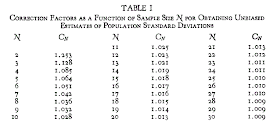
In fact, here are the correction factors for S, as given by Holtzman (where his "N" is our "n", the sample size):
 For the case of the regression model, I've calculated values for cn, for various small values of n and k:
For the case of the regression model, I've calculated values for cn, for various small values of n and k:
A more detailed table is available here.
You won't find these two issues discussed in your typical econometrics textbook, but it's really not difficult to address them properly. To heck with "signing" the bias of s as an estimator of σ, let's get some exact results!
Before we start, there's one really important thing that has to be noted. The unbiasedness of S2 or (s2) as an estimator of σ2 doesn't require that the population follows any particular distribution (such as normal). The population distribution just has to have finite first and second moments, so that σ2 is actually defined. On the other hand, the following results relating to unbiased estimation of σ itself require that we are sampling from a normal population.
With that in mind, let's see what Holzman (1950) had to say about all of this. He provided a really simple proof that E[CnS] = σ, where n is the sample size and the constant, Cn, is defined as:
Cn = {Γ [(n - 1) / 2] [(n - 1) / 2]1/2} / Γ(n /2) .
It follows, trivially, that E[cns] = σ, where:
cn = {Γ [(n - k) / 2] [(n - k) / 2]1/2} / Γ [(n - k + 1) / 2] .
So, both S and s are biased estimators, with biases given by B = (σ / Cn) - σ, and b = (σ /cn) - σ, respectively.
Another way to get to the same result is a follows. Given the assumption of a normal population, the statistics (n - 1) S2 / σ2 and (n - k)s2 / σ2 are each chi-square distributed with (n - 1) and (n - k) degrees of freedom, respectively. The (positive) square root of a chi-square random variable follows what's called a Chi distribution. If you're aware of this, you can then use knowledge of the mean of that distribution to get the results established by Holzman. Of course, the math. that's needed to derive the expression for that mean (if you don't where to look it up) is precisely the same as we've just been through!
Looking at the expressions for the biases of S and s, and their bias-adjusted counterparts, it's pretty clear that the sample size, n, doesn't have to be terribly big before the bias becomes negligible. (Asymptotically, both estimators are weakly consistent for σ. This follows from the consistency of S2 and s2 for σ2, and the application of Slutsky's theorem. So, S and s are asymptotically unbiased for σ.)
In fact, here are the correction factors for S, as given by Holtzman (where his "N" is our "n", the sample size):

n k = 2 k = 3 k = 4
5 1.085402 1.128379 1.253314
10 1.031661 1.036237 1.042352
15 1.019398 1.021027 1.022956
20 1.013979 1.014806 1.015737
25 1.010925 1.011424 1.011971
30 1.008967 1.009300 1.009659
A more detailed table is available here.
I should also mention that this general topic was discussed in a very readable manner by Jarrett (1968), Cureton (1968), Bolch (1968), Brugger (1969), and Gurand and Tripathi (1971). In particular, Jarrett provides an interesting summary of the history of the correction discussed by Holtzman, and provides much earlier references.
Finally, consider the following OLS regression result:

Similarly, the reported standard errors, whose values are 0.499569 and 0.308727 are (downward) biased estimates of the true standard deviations of the OLS estimators of the intercept and slope coefficients. The corresponding unbiased estimators of those standard deviations are easily computed to be 0.5066 and 0.3130 respectively.
Of course, the reported (biased) standard errors still have to be used to construct appropriate confidence intervals for the coefficients of the model, and to compute the t-statistics (as shown in the above output). Otherwise the usual "t-ratios" that are used in each case won't be Student-t distributed - they'll just be proportional to a Student-t random variable.
References
Bolch, B. W., 1968. More on unbiased estimation of the standard deviation. American Statistician, 22(3), 27.
Brugger, R. M., 1969. A note on unbiased estimation of the standard deviation. American Statistician, 23(4), 32.
Cureton, E. E., 1968. Unbiased estimation of the standard deviation. American Statistician, 22(1), 22.
Gurland, J. and R. C. Tripathi, 1971. A simple approximation for unbiased estimation of the standard deviation. American Statistician, 25(4), 30-32.
Holtzman, W. H., 1950. The unbiased estimate of the population variance and standard deviation. American Journal of Psychology, 63, 615-617.
© 2013, David E. Giles
Nice !
ReplyDeletebut do you have something similar for the inverse of the standard deviation, since usually it is the inverse that is used as a normalizing factor ?
That can easily be done by setting r= -1/2, rather than r = 1/2, in Holtzman's short proof. Of course, the reason for normalizing, usually, is to obtain a pivotal statistic for testing purposes, in which case the form of the resulting distribution is important, so see the closing paragraph n my post.
DeleteHi Dave,
ReplyDeletevery nice article, thanks! Do you know about similar correction factors for other non-linear functions such as exp?
Best,
David
Jensen's Inequality will tell you the direction of the bias in many cases (e.g., exp and log). Then it's just a matter of doing the integration on a case by case basis. I don't have a reference,
Delete