In the early part of my recent post on this series of posts about Monte Carlo (MC) simulation, I made the following comments regarding its postential usefulness in econometrics:
".....we usually avoid using estimators that are are "inconsistent". This implies that our estimators are (among other things) asymptotically unbiased. ......however, this is no guarantee that they are unbiased, or even have acceptably small bias, if we're working with a relatively small sample of data. If we want to determine the bias (or variance) of an estimator for a particular finite sample size (n), then once again we need to know about the estimator's sampling distribution. Specifically, we need to determine the mean and the variance of that sampling distribution.
If we can't figure the details of the sampling distribution for an estimator or a test statistic by analytical means - and sometimes that can be very, very, difficult - then one way to go forward is to conduct some sort of MC simulation experiment."Before proceeding further, let's recall just what we mean by a "sampling distribution". It's a very specific concept, and not all statisticians agree that it's even an interesting one.
We need to begin by defining a very basic concept - that of a "statistic".
A statistic is just some function of the random data in our sample. So, each individual sample value is a statistic. So is the the sum of the sample values; the difference between any two sample values; the variance of the sample numbers; etc. Because a statistic is a function of the random sample values, it is itself a reandom variable. The sample average, the sample standard deviation, etc., are all random variables - and as such they are all described by a probability distribution. We use the special name "sampling distribution" when we're talking about the probability disrtibution of a statistic, rather than just any old random variable.
Estimators and test statistics are (almost always) constructed form our random sample data. Think of using the sample average as an estimator of the population mean. Or recall that the formula for the least squares regression estimator uses the data for the (random) dependent variable. Estimators are statistics - their random behaviour is described by their sampling distributions.
Now comes the controversial part of all of this.
In classical statistics, as opposed to Bayesian statistics, the sampling distribution is of paramount importance. It forms the basis for measuring the "quality" of estimators and tests. Why is the sampling distribution controversial to some? Well, it's because it is built on the following hypothetical thought experiment. In that "experiment" we draw a random sample of size "n" from the population and we construct the value, "s" of the statistic of interest, "S". We note this value and then we draw another, independent, random sample of size "n", and calculate the new value of "s". We keep doing this, keeping track of the various (randomly distributed) values "s" that we generate. In principle we would keep doing this forever! Then we'd have every conceivable value of "s" that can occur, and we'd be able to observe the frequency (and relative frequency) with which each of those values occurs. These values of "s", and their probabilities (long-run relative frequencies) of occurring together make up the probability distribution, or sampling distribution of the statistic, "S".
This is of interest if we think of probabilities in terms of long-run relative frequencies. But these are based on this idea of repeated sampling. What if we're in a situation where repeated sampling isn't possible, and we have to go forward on the basis of just a single sample? (That is, conditional on the information in one sample.) Then the very concept of the sampling distribution really is no longer all that interesting. We also need a different way of defining what we mean by a "probability". That's where Bayesian statistics and econometrics comes into the picture, but more on that another day!
So, when we conduct a MC simulation experiment what we're trying to do is to replicate (simulate) a sampling distribution - in principle we need to use an infinite number of replications. Obviously, we can't do this literally!. By using only a finite number of replications (e.g., 1,000 or even 100,000) we incur some simulation error. It's inevitable. If that error is quite small (in some sense) then there's probably not too much to worry about. But how would we know that this was the case?
It's natural to ask, "Can we reduce the variability associated with our MC simulation results without incurring unreasonable computational cost?" The answer is "Yes - there are several ways of doing this". You might guess that increasing the number of replications should help in this respect - we saw that when discussing the estimation of integrals in the first MC post. But there are other ways too, and I'll discuss this further in a subsequent post.
Now, let's relate all of this to the specific problem of determining the bias, and efficiency, of some estimator. In the case of its bias we want to compare the expected value of the estimator with the true value of the parameter that we're trying to estimate. More completely, we need to compare the mean of the sampling distribution of the estimator with the true parameter value. Recall how we define the mean of a random variable (such as an estimator, or any other "statistic"). If the statistic is called S (with values s), then the mean of the sampling distribution of S is E[S] = ∫ sp(s)ds. where p(s) is the sampling distribution of S. Sometimes we can work out E[S] quite easily, and exactly.
In many cases, however, the evaluation of the integral associated with E[S] may be really difficult. If we're going to approximate that integral, so that we can approximate E[S], then we want to make that approximation as accurate as possible. Again, think back to the discussion about approximating integrals in the first MC post.
Suppose that S is an estimator (say θ*) of some parameter (θ), and we construct θ* from some random sample data (y) that are drawn from a population that depends on θ, then what we're trying to do is get an accurate approximation of Bias[θ*] = E[θ*] - θ = ∫ θ*(y)p(y|θ)dy - θ.
(Note that y will typically be a vector, of length equal to the sample size, and θ may also be a vector. Typically, this will make the above integration problem more complex.)
So, there certainly is a very obvious connection between the problem of simulating an integral, and that of trying to determine the bias of an estimator.
For this specific problem, the steps involved in conducting the most basic MC experiment would be something like the following:
1. Assign a "realistic", or interesting, value to θ. (The results will be conditioned on this choice, so the whole exercise may need to be repeated lots of times, for different values
of theta, because in reality θ is unknown. I'm not going to talk about "bootstrapping" here.)
2. Generate a random sample of fixed size (say, n) from p(y | θ).
3. Compute the value of θ*, based on this particular y vector, and store this value.
4. Repeat steps 2 and 3 many, many times. Suppose the number of replications that you decide to use is N.
5. You will now have N different values of θ*, each based on a different (independent) sample of size n.
When you look at the empirical distribution of these N values - in a table, or in a histogram - what you're looking at is an approximation to the sampling distribution of the statistic, θ* that you're interested in. It's an approximation, because N is finite. And, of course, this sampling distribution will (in general) depend on your choices of values for θ and for n. You can now vary these values to get a more complete picture of what's going on.
To approximate E[θ*] you can just use the arithmetic average of N values of θ* that you've generated. Why is this justified? Because the (strong) Law of Large Numbers ensures that the sample average converges in probability to the population expectation as N becomes infinitely large, given that we have independent sampling.
The difference between this empirical average and the value that you assigned to θ itself will give you an approximation to the bias of θ*. Remember, the value of this bias that you come up with may very well change as you change n or θ. It may not - e.g., the difference will be zero for all n and all θ values if θ* is an unbiased estimator, and if your sampling experiment is accurate enough for you see this numerically.
The following EViews program code illustrates these steps for the particular case where the population distribution, p(y | theta), is Uniform on [0 , 1]. So, this automatically assigns the true population mean to be E[Y] = μ = 0.5. SImilarly, the true population variance is V[Y] = σ2 = (1 / 12).
rndseed 123456
!nrep=100
!n=9
vector(!nrep) av
series y
smpl 1 !n
for !i=1 to !nrep
y=@runif(0,1)
av(!i)=@mean(y)
next
smpl 1 !nrep
mtos(av, xbar)
show xbar
hist xbar
The MC simulation itself, which really involves just the four lines of code in blue, then produces the sampling distribution for a particular statistic - the sample average - when the sample size is very small, namely n = 9. The simulation involves just N = 100 replications of steps 2 and 3 mentioned above.
If you go to the entry for this post on the blog's "Code" page you'll find an annotated version of this EViews program code with lots of comments. You can open that program with any text editor - you don't need EViews. You'll also find my EViews workfile on the "Code" page if you need it.
Here is the (unscaled) histogram approximating the sampling distribution for the sample average that you get when you run the above code:
 If we now think about using the sample average as an estimator of the population mean, whose true value is 0.5 in this case, you can see that we get the impression that this estimator might be unbiased. The mean of (this rough approximation to) the sampling distribution is 0.485. That's pretty close to the value 0.5.
If we now think about using the sample average as an estimator of the population mean, whose true value is 0.5 in this case, you can see that we get the impression that this estimator might be unbiased. The mean of (this rough approximation to) the sampling distribution is 0.485. That's pretty close to the value 0.5.
Let's be a bit more serious about this, and replicate the experiment N = 100,000 times, rather than just 100 times. After all, hypothetically we should be using an infnite number of replications. Here's what we get:
 Now we see that the mean of the sampling distribution (for the sample average) is almost exactly 0.5. And you know why this is the case. We've used independent sampling, so the sample average is an unbiased estimator of the population mean, for any population that has a finite mean.
Now we see that the mean of the sampling distribution (for the sample average) is almost exactly 0.5. And you know why this is the case. We've used independent sampling, so the sample average is an unbiased estimator of the population mean, for any population that has a finite mean.
If you didn't know this result already, then you might at least start to suspect that we have an unbased estimator here, at least for the Uniform distribution when n = 9.
By the way, the sampling distribution in Figure 2 is not that of a Normal distribution, and it shouldn't be because the population distribution is Uniform and we've averaged just 9 observations. In fact it takes the form of an Irwin-Hall distribution, and if we had n = 2, for instance, this would become a triangular distribution. (See this previous post.)
Another consequence of using (simple) random sampling is that the variance of the sampling distribution for the sample average - that is, the variance of the sample average - is (σ2 / n). Recalling that in our case σ2 = (1/12), and n = 9, the standard deviation of the sampling distribution in this example should be 0.096225. If you look at ther results in Figure 2, you'll see that things line up nicely. The standard deviaiton, or the variance, of the estimator gives us the basis for measuring its efficiency relative to that of other potential estimators.
There are lots of other things that we could extract from this example, but let's just do one more thing at this point. Let's increase the sample size, n, to 144 and see what happens. The reason for doing this is to illustrate the (Lindeberg-Lévy) Central Limit Theorem. This tells us that at least when n becomes infinitely large the sampling distribution of the sample average should become Normal, even though the population that we're sampling from is non-Normal.
With just N = 100 replications (as in Figure 3 below) we see that we have a rather poor approximation to the actual sampling distribution. The skewness coefficient should be zero, and the kurtosis coefficient should be 3.
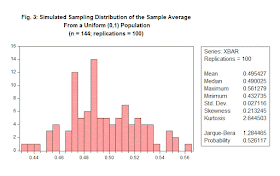
 The standard deviation of the sampling distribution should be 0.0241, which we've pretty much nailed it. Of course, this is much smaller than in Figure 2 because n is larger and what we're seeing is the consistency of the sample average as an estimator of the population mean. (Note that the scale for the horizontal axis in Figure 4 is different from that in Figure 2.) We can also see that that there's negligible skewness, and the kurtosis coeficient is very close to 3 in value. (You can also look at the Jarque-Bera test result, but keep in mind that the J-B test is only valid asymptotically, and we still only have n = 144 for our sample size.)
The standard deviation of the sampling distribution should be 0.0241, which we've pretty much nailed it. Of course, this is much smaller than in Figure 2 because n is larger and what we're seeing is the consistency of the sample average as an estimator of the population mean. (Note that the scale for the horizontal axis in Figure 4 is different from that in Figure 2.) We can also see that that there's negligible skewness, and the kurtosis coeficient is very close to 3 in value. (You can also look at the Jarque-Bera test result, but keep in mind that the J-B test is only valid asymptotically, and we still only have n = 144 for our sample size.)
However, as it turns out, for this particular problem, this sample size is actually plenty large enough for the Central Limit Theorem to "kick in". We can see this if we increase the sample size to n = 1,000, as in Figure 5:
 Apart from the (inevitable) further reduction of the variance of the sampling distribution (and note the scale of the horizontal axis, again), the results really aren't that much different from those in Figure 4. The asymptotic Normality of our estimator of the population mean is really clear.
Apart from the (inevitable) further reduction of the variance of the sampling distribution (and note the scale of the horizontal axis, again), the results really aren't that much different from those in Figure 4. The asymptotic Normality of our estimator of the population mean is really clear.
Aside: In the above discussion of the asymptotic results I've deliberately chosen not to scale the sample average by √(n) to deal with the degeneracy of the limiting distribution. Remember, this is supposed to be a really basic introduction to MC simulation, not a comprehensive discussion of asymptotics.
Hopefully, what you'll take away from this post is a basic understanding of how we can exploit the notion of the "sampling distribution", and our ability to generate (pseudo-) random numbers on a computer, to learn about the properties of important statistics such as the estimators that we use.
There's much about all of this to come in the follow-up posts.
The difference between this empirical average and the value that you assigned to θ itself will give you an approximation to the bias of θ*. Remember, the value of this bias that you come up with may very well change as you change n or θ. It may not - e.g., the difference will be zero for all n and all θ values if θ* is an unbiased estimator, and if your sampling experiment is accurate enough for you see this numerically.
The following EViews program code illustrates these steps for the particular case where the population distribution, p(y | theta), is Uniform on [0 , 1]. So, this automatically assigns the true population mean to be E[Y] = μ = 0.5. SImilarly, the true population variance is V[Y] = σ2 = (1 / 12).
rndseed 123456
!nrep=100
!n=9
vector(!nrep) av
series y
smpl 1 !n
for !i=1 to !nrep
y=@runif(0,1)
av(!i)=@mean(y)
next
smpl 1 !nrep
mtos(av, xbar)
show xbar
hist xbar
The MC simulation itself, which really involves just the four lines of code in blue, then produces the sampling distribution for a particular statistic - the sample average - when the sample size is very small, namely n = 9. The simulation involves just N = 100 replications of steps 2 and 3 mentioned above.
If you go to the entry for this post on the blog's "Code" page you'll find an annotated version of this EViews program code with lots of comments. You can open that program with any text editor - you don't need EViews. You'll also find my EViews workfile on the "Code" page if you need it.
Here is the (unscaled) histogram approximating the sampling distribution for the sample average that you get when you run the above code:

Let's be a bit more serious about this, and replicate the experiment N = 100,000 times, rather than just 100 times. After all, hypothetically we should be using an infnite number of replications. Here's what we get:

If you didn't know this result already, then you might at least start to suspect that we have an unbased estimator here, at least for the Uniform distribution when n = 9.
By the way, the sampling distribution in Figure 2 is not that of a Normal distribution, and it shouldn't be because the population distribution is Uniform and we've averaged just 9 observations. In fact it takes the form of an Irwin-Hall distribution, and if we had n = 2, for instance, this would become a triangular distribution. (See this previous post.)
Another consequence of using (simple) random sampling is that the variance of the sampling distribution for the sample average - that is, the variance of the sample average - is (σ2 / n). Recalling that in our case σ2 = (1/12), and n = 9, the standard deviation of the sampling distribution in this example should be 0.096225. If you look at ther results in Figure 2, you'll see that things line up nicely. The standard deviaiton, or the variance, of the estimator gives us the basis for measuring its efficiency relative to that of other potential estimators.
There are lots of other things that we could extract from this example, but let's just do one more thing at this point. Let's increase the sample size, n, to 144 and see what happens. The reason for doing this is to illustrate the (Lindeberg-Lévy) Central Limit Theorem. This tells us that at least when n becomes infinitely large the sampling distribution of the sample average should become Normal, even though the population that we're sampling from is non-Normal.
With just N = 100 replications (as in Figure 3 below) we see that we have a rather poor approximation to the actual sampling distribution. The skewness coefficient should be zero, and the kurtosis coefficient should be 3.

However, when we use N = 100,000 replications, the real picture emerges, as in Figure 4:

However, as it turns out, for this particular problem, this sample size is actually plenty large enough for the Central Limit Theorem to "kick in". We can see this if we increase the sample size to n = 1,000, as in Figure 5:

Aside: In the above discussion of the asymptotic results I've deliberately chosen not to scale the sample average by √(n) to deal with the degeneracy of the limiting distribution. Remember, this is supposed to be a really basic introduction to MC simulation, not a comprehensive discussion of asymptotics.
Hopefully, what you'll take away from this post is a basic understanding of how we can exploit the notion of the "sampling distribution", and our ability to generate (pseudo-) random numbers on a computer, to learn about the properties of important statistics such as the estimators that we use.
There's much about all of this to come in the follow-up posts.
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.