Spring is sprung and wedding season is fast approaching. Indeed, some couples have already taken the plunge this Spring. On 28 April, the day before Will and Kate got hitched (sorry - before the Royal nuptials of Prince William and Catherine Middleton), The Economist magazine's Daily Chart showed the average age at first marriage for males and for females in the United Kingdom, from 1890 to 2010. The piece that accompanied with the chart went under the jolly title of "The Royal We", and discussed trends in marriage ages with markers at various key royal wedding dates over the years.
Several features of the chart were pretty much as you'd anticipate:
Several features of the chart were pretty much as you'd anticipate:
- The average age for grooms exceeds that for brides.
- There were structural breaks around the end of the First and Second World Wars.
- Since about 1970, the average marriage age has been trending upwards (from about 22 and 24 years of age for brides and grooms in 1970; to about 29 and 31 years of age, respectively, in 2010).
Always on the look-out for some new examples for my classes - especially ones that are a little bit "different" in their content - I thought it would be interesting to explore some similar data for U.S. pairings. The following chart shows the median age at first marriage for happy couples entering marriage for the first time between 1947 and 2010. The data are from the U.S. Census Bureau, and are available in the Excel workbook on the Data page that goes with this blog.
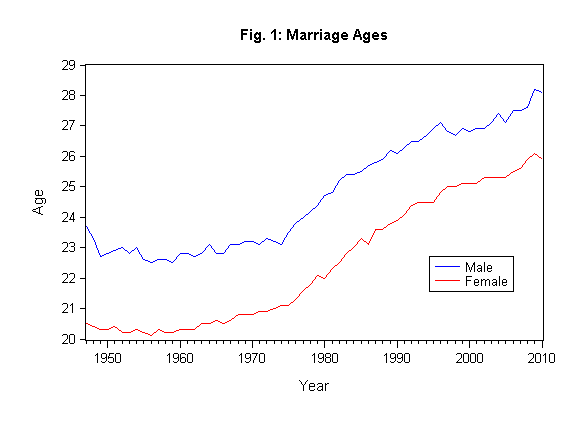
The general trend is similar to that for the U.K. over this period.
So, here's what I want to find out. Is there also some long-run equilibrating force that stops the ages of brides and grooms from "drifting apart" over time? Or, are we eventually going to end up with lots of old guys engaging in cradle snatching, or maybe even lots of "cougars" marrying young guys?
In econometric terms, we can re-phrase this question as:
"Are these two time-series cointegrated?"Why don't we find out?
Here's the road map of where we're going:
- Test each series to see if both of them are non-stationary, and have the same order of integration.
- Make sure that the testing in step 1 takes account of the fact that there seems to be a break in the trend in 1975, in each series.
- If both series are (say) I(1), then construct a VAR model for the 2 variables - this will require choosing the maximum lag-length.
- Test the residuals of the VAR model to see if the errors are (a) independent; and (b) normally distributed.
- Use Johansen's methodology to test if the 2 series are cointegrated.
- In step 6, we'll have to again take account of the structural breaks in the trends of the data. To do this, we'll use the methods introduced by Johansen et al. (2000).
A couple of things to notice here before we get underway.
First, to test for unit roots in the presence of a structural break in the trend, I'm just going to use Perron's (1989) test. Be aware that there was an error in one of the key tables of critical values in his original paper, and this was later corrected by Perron and Vogelsang (1993). There are other tests that I could also use, but I want to put most of the emphasis on the cointegration testing with structural breaks, because this is less well-known in the applied literature.
Second, step 4 is pretty important for the following reason. When we move to Johansen's testing procedure it is based on the likelihood function. The latter is set up assuming independence and normality. So, if these conditions aren't satisfied we may have a problem with what then follows.
With those words of explanation, let's get underway. As usual, the EViews workfile for all of this is available on the Code page that accompanies this blog. Check out the "Read_Me" text object in the workfile for more details.
When I test the 2 time-series for their order of integration, with no allowance for the structural break (yet) this is what I get:
ADF
|
Outcome
|
KPSS
|
Outcome
| |
Male
|
-3.766
|
I(0)
|
0.185
|
I(1)
|
Female
|
-2.941
|
I(1)
|
0.207
|
I(1)
|
In the case of the ADF tests I've allowed for a drift and trend in the Dickey-Fuller regressions; and in the case of the KPSS tests the null is that the series is trend-stationary. So far, I'd conclude that the 2 series are I(1), but let's take account of the trend break in 1975. This is important, because the regular ADF test tends to "discover" unit roots that aren't actually there, when there are breaks in the data. Keep in mind that we can't test for cointegration if one or both the series is actually stationary.
The situation we're facing is about as tidy as it can get. There is a break in the trend at a single and easily determined point in the sample. This is Perron's Case 'B'.
For each time-series I'll do the following. I'll regress the series by OLS on an intercept, a linear trend variable (t in the EViews workfile), and a variable DT*. This last artificial variable takes the value zero up to and including 1975, and then the values 1, 2, 3,.....etc. to the end of the sample. The residuals from this first-stage regression are then tested for a unit root, using the ADF test with the "no drift-no trend" option for the Dickey-Fuller regression. This last point is important because the data have been filtered already for the drift and trend (with the break) in the first-stage regression.
The resulting ADF test statistics are -1.478 and -1.294 respectively for the MALES and FEMALES series. However, the usual critical values don't apply (even asymptotically) for this modified ADF test. Instead, we need to use Perron's asymptotic critical values (as corrected by Perron and Vogelsang (1993). The single break in the trend, in 1975, occurs at λ = 0.44 (44%) of the way through the sample. So, the 5% and 10% critical values are approximately -3.92 and -3.62 respectively. Clearly, we cannot reject the null of a unit root for either series.
Keep in mind that we have only 64 observations - not a very big sample. So, in a situation like this we might want to consider bootstrapping the critical value for the Perron-ADF tests, specific to our set of data and sample size. Not today, though, especially as the outcome of these last tests is not "borderline"!
O.K., so we've completed Step 2 in our road map. We're now in a position to test for cointegration between the male and female median first-marriage ages. When I fit a VAR model in the levels of the data, and use the usual information criteria (AIC, SIC, HQ, FPE) to determine the optimal maximum lag length, they all suggest just one period. That's O.K., but when we use the VAR model for cointegration testing we'll be differencing the data, so a second lag would be a good idea. An extra lag for the variables in the model isn't a bad idea here, anyway, to make sure that the residuals are "clean". So, I'm settling on a maximum lag length of k = 2 for the VAR model.
Recall Step 4 - apply some specification tests to this VAR model. Here are the results of testing for serial independence of the errors, using an LM test:
Lags
|
LM
|
p-value
|
1
|
7.169
|
0.127
|
2
|
1.866
|
0.760
|
3
|
7.200
|
0.126
|
4
|
7.903
|
0.095
|
5
|
1.592
|
0.810
|
6
|
8.589
|
0.072
|
When we test if the errors are normally distributed, we get the following results:
Variable
|
Jarque-Bera
|
d.f.
|
p-value
|
Male
|
1.945
|
2
|
0.378
|
Female
|
3.972
|
2
|
0.137
|
Joint
|
5.917
|
4
|
0.206
|
So far, so good. Now for the slightly trick part (Steps 5 and 6 on the path to cointegration bliss). We need to allow for those breaks in the trends of the male age and female age time-series when we implement Johansen's testing procedure. We're going to use the methods introduced by Johansen et al. (2000). Joyeux (2007) provides a very readable discussion of these methods, together with a nice application. Roselyne really knows her stuff, having done some of the seminal work on long-memory processes and fractional differencing, and I strongly recommend her paper to you.
What I need to do first, is to construct two dummy variables:
D2,t = 0 (t = 1947, ...., 1975); = 1 (t = 1976, ..., 2010)
I2,t = 1 (t = 1976) ; = 0 (elsewhere).
Then, when I set up the VAR model for the Johansen testing procedure, I include the following exogenous variables in the model:
- (Linear) trend
- D2,t-k (where k, the maximum lag length, is 2 in our case)
- Trend*D2,t-k
- I2,t ; I2,t-1; ......; I2,(t-(k-1); where again, k = 2 in our case.
We then construct the usual Johansen trace test statistics.
This is what Johansen et al. (2000) call the Hl(r) test. The asymptotic distribution of the test is different from what it would usually be for the trace test. The asymptotic critical values depend on the proportion of the way through the sample that the break occurs (λ = 0.44 in our case); and on (p - r), where p is the number of variables under test p = 2, here), and r is the cointegrating rank being tested. So, for us, r = 0, 1. Note that the test can be modified to allow for two structural breaks.
This is what Johansen et al. (2000) call the Hl(r) test. The asymptotic distribution of the test is different from what it would usually be for the trace test. The asymptotic critical values depend on the proportion of the way through the sample that the break occurs (λ = 0.44 in our case); and on (p - r), where p is the number of variables under test p = 2, here), and r is the cointegrating rank being tested. So, for us, r = 0, 1. Note that the test can be modified to allow for two structural breaks.
On the Code page for this blog there is a second EViews workfile, and an accompanying program file, that can be used to generate the asymptotic critical values for the Hl(r) test (and a second test), for various values of (p - r) and λ.
In EViews, I use option 4 as far as the deterministic trend specification is concerned. For our λ, the results of the Hl(r) cointegration tests are as follows:
In EViews, I use option 4 as far as the deterministic trend specification is concerned. For our λ, the results of the Hl(r) cointegration tests are as follows:
No. of cointegrating equations
|
Hl(r)
|
10% Critical Value
|
5% Critical Value
|
Outcome
|
Zero
|
40.943
|
34.393
|
37.346
|
Reject
|
At Most 1
|
15.667
|
16.761
|
18.906
|
Do Not Reject
|
A final observation. We saw that whether or not we allowed for the structural breaks in the data, we concluded that both of the time-series are I(1). However, if we don't allow for the structural breaks when undertaking the cointegration testing, it turns out that we come to the rather strange conclusion that there are two cointegrating relationships between the male and female marriage age series. You can easily check this yourself - see the EViews workfile. However, this result makes no sense! When we have only two I(1) time-series, the maximum number of cointegrating relationships is one - and if it's one, then the cointegrating vector is unique.
In other words, failing to use the appropriate methodology when testing for cointegration gives us the result we deserve: garbage! Here, doing the job properly really pays off.
Note: The links to the following references will be helpful only if your computer's IP address gives you access to the electronic versions of the publications in question. That's why a written References section is provided.
References
Johansen, S., R. Mosconi and B. Nielsen (2000). Cointegration analysis in the presence of structural breaks in the deterministic trend. Econometrics Journal, 3, 216-249.
Joyeux, R. (2007). How to deal with structural breaks in practical cointegration analysis? In B. B. Rao (ed.), Cointegration for the Applied Economist, Second Edition , Palgrave Macmillan, New York, 195-221.
, Palgrave Macmillan, New York, 195-221.
Professor Giles
ReplyDeleteThank you for taking the time to write the blog. I like the idea of a more informal communication of econometrics and it is interesting to learn how you think of things I work with myself.
I have some questions to and comments on your cointegration analysis. When I was visiting NYU I saw treatments similar to yours and hence I speculate if it is the standard North American way to do cointegration analysis. I was taught a bit differently here in Copenhagen and I would like to hear your thoughts on the pros and cons.
We like to analyse the data through just one model. When I see your treatment the order of integration is determined through two different models, one for each series, and then the cointegration hypothesis is examined in a third model, the VECM, through rank determination of the Pi matrix. Why not just do the following:
- Fit a VECM with deterministic components and lags enough to be well specified.
- Determine the number of stochastic trends through the trace test.
- Analyse (non-)cointegration properties through exclusion restrictions on the cointegration vector.
- Do tests of other hypotheses on the cointegration and adjustment vectors
I think it is appealing to work in just one model and furthermore you avoid the problem that parameters in two different models are not easy to compare.
Another thing: I think you have made a mistake in the model specification. Unfortunately I don not have access to Eviews but in OxMetrics I am able to reproduce your results. The problem is that the second trend variable is not restricted to the cointegration space. When restricted the results actually change to rejection of cointegration against the trend-stationary alternative. The following Ox code should reproduce both results.
#include
#import
main()
{
decl model = new PcFiml();
model.SetPrint(FALSE);
model.Load("Marriage.xls");
model.Deterministic(FALSE);
model.Append(zeros(29, 1) | ones(2010 - 1947 - 29 + 1, 1), "Sh76");
model.Append(model.GetVar("Sh76") .* model.GetVar("Trend"), "Tr76");
model.Append(zeros(29, 1) | 1 | zeros(2010 - 1947 - 29, 1), "I76");
// David Giles' model
model.Select(Y_VAR, {"Men", 0, 2});
model.Select(Y_VAR, {"Women", 0, 2});
model.Select(X_VAR, {"Trend", 0, 0}); // Only the whole preiod trend is restricted
model.Select(U_VAR, {"Constant", 0, 0, "Tr76", 2, 2, "Sh76", 2, 2, "I76", 0, 1});
model.SetSelSample(-1, 1, -1, 1);
model.Estimate();
model.SetPrint(TRUE);
model.Cointegration();
model.SetPrint(FALSE);
model.DeSelect();
// Model with restricted broken trend
model.Select(Y_VAR, {"Men", 0, 2});
model.Select(Y_VAR, {"Women", 0, 2});
model.Select(X_VAR, {"Trend", 0, 0, "Tr76", 2, 2}); // Both trend variables are restricted
model.Select(U_VAR, {"Constant", 0, 0, "Sh76", 2, 2, "I76", 0, 1});
model.SetSelSample(-1, 1, -1, 1);
model.Estimate();
model.SetPrint(TRUE);
model.Cointegration();
model.DeSelect();
delete model;
}
I agree with this. We have to have the dummy-trend interaction inside the levels matrix (i.e., the error correction matrix) and not as an exogenous series. This is required for the correct usage of the LikelihoodRatio{H_l(r)|H_l(p)} test (see equation (2.6) of Johansen et al. (2000), the LR test is testing for the rank of alpha*[beta,gamma]). This is similarly true for a simple level shift, otherwise the null distribution of the H_c(r) test statistic doesn't apply. This can all be done easily in R if you modify the ca.jo function of the urca package (anyone that wants to code ... reply to this), or I think that it can be done in the point and click JMulti software. Unfortunately there's currently no Eviews functionality for this.
DeleteThanks for pointing this out.
DeleteHi,
DeleteThanks for this excellent blog.
I have been working on a similar project and am having hard time to deal with the problem. I have two structural breaks in my data.
I tried Jmulti, but it gives me inconsistent results. As mentioned here, apparently Eviews is not capable of restricting trend dummy inside the error correction matrix. Also, Joyeux(2007, p.214) makes the same point under the "Deterministic components" when she was comparing capabilities of different programs.
I do not have access to Microfit,MALCOLM, and CATS.
I am using R but could not modify R's urca package for structural break.
Can anybody kindly provide an R code for this problem? Any help would greatly be appreciated!
Thanks !
Serkan
Serkan - let's see if anyone can help out.
DeleteAnyone has the code to perform the test in R?
DeleteHi, I am currently also trying to implement it with R, so it would be great if we could get the code included in upstream, so that it might be possible to directly estimate the Johansen et al. (2000) procedure with R.
DeleteYou can download our R code from here: http://web.uvic.ca/~dgiles/downloads/johansen/index.html
DeleteHi, sorry for returning to this post, but it is a very important and really one of the very few sources of implementing Johansen cointegration test with structural breaks. Anonymous above pointed that restricting the trend-dummy interaction can be easiliy done in ca.jo() from urca package in R. But I am not sure how to do it. Can someone help me pelase?
DeleteThank you so much!
Marcus
Andreas: Thanks for the very thoughtful comment. I think there is a very strong case indeed for working with the one model, as you suggest. In many ways it makes more sense than the way a lot of us usually proceed. Thanks for the comment abuot the trend - I'll check that out.
ReplyDeleteMuch appreciated!
Reading this blog is better than reading an econometric journal. Journal articles are not reader friendly.
ReplyDeleteGood job Dr. Giles!
Lenard (Philippines)
Lenard: Thanks for the comment. I'm glad it helps, but don't stop reading the journals!
ReplyDeleteDear Professor Giles:
ReplyDeleteThank you for the excellent information; very helpful. However, I have a question about the number of lags in Johansen cointegration test. Suppose that I tested for cointegration between two series that have structural breaks without considering the breaks and determined the number of lags to be, for example 5. When considering the breaks, do I have to go back and determine the number of lags? In other words, would including the breaks affect the number of lags, or I should be using the same number of lags as in the case without breaks, that is 5.
Thanks,
Sal
Dear Professor Giles,
ReplyDeleteI was so happy to come across your blog, it has been very helpful. In my dataset of education and democracy in France, I find that education has one structural break whilst democracy has three. When I use the level, pulse and trend dummies that you outline in the VAR, I get the results that I hope for e.g.lags of education have significant effects on democracy but not the reverse. But the coefficients are very large, e.g. greater than 100, which is surely improbable as the range of my democracy variable is 0-100. Is this a sign that the model is misspecified? What can I do to correct this?
Thank you very much for your help.
Kind regards,
Christy
Dear Professor Giles,
ReplyDeleteFirst of all, thank you so much for the EViews code! It is magic! Now I just need to edit three lines and I can produce critical values of a non-standard asymptotic distribution!
I agree with Andreas that your trend terms were not correctly restricted. Referring to Johansen et al. (2000) (I am using his notations which are slightly different from yours), the two interaction terms, (E1,t)*t and (E2,t)*t should enter the cointegrating vector and hence be restricted (Ej,t is a dummy taking value of 1 if observation t belongs to the jth subsample, but not the first k observations of that subsample). k=2 in our case. The unrestricted variables entering the ECM should be E1,t, E2,t, D2,t-1, and D2,t-2 (Dj,t-i is a dummy for the ith observation in the jth subsample). This is hardly your fault, because EViews does not allow non-standard trend terms entering the cointegrating vector. As far as I know, only Oxmetrics’ PcGive allows one to enter (E1,t)*t and (E2,t)*t in the cointegrating vector.
Here is my question: I am currently doing some research using similar cointegration approach. My series are cointegrated using normal Johansen rank test. Then I identified a structural break using economic theory (suppose the break is correctly identified) but when I applied Johansen et al.(2000) Hl(c) model and checked against critical values generated from your code, I found no cointegration. This made me think about what Andreas said above. She mentioned if your trend terms were restricted correctly, the result would be no cointegration. But clearly your two series looked like cointegrated, so did mine! My intuition is that by restricting such complicated terms into the cointegrating vector, either we lose power or the complicated deterministic terms take away so much explanatory power from the stochastic component. What are your suggestions? Thank you very much.
Ben
Ben - thanks for the comments. I agree - it's almost certainly loss of power (maybe coupled with relatively small sample size).
Deletethanks
ReplyDeleteDear Prof Giles,
ReplyDeleteI find your blog very helpful for my learning! I wish more professors would do this and I think this is great community service.
Why is it that you don't allow for a structural break when you do the VAR in levels to select optimal lag length? Is it because these dummies enter the VECM as exogenous variables? Would you always exclude the exogenous variables that will enter the VECM from the levels VAR when you're selecting lag length?
Thanks.
Prof. Giles,
ReplyDeleteWhen doing the Johansen Cointegration Test involving one variable which is a price level, do I need to deflate it to transform in real terms or it is best to use nominal values?
Thanks.
Generally speaking, if you're using the standard Johansen procedure, you'll want all of the variables to be I(1). Some price level variables are I(2), so this will complicate matters.
ReplyDeleteIn terms of your main question, the key thing is that the variables you use in the cointegration testing are the ones that you are actually interested in, from an economic perspective, in the context of the modelling that you are doing. This is what should determine whether you deflate or not (and then you worry about whether or not all of the variables are of the same order of integration, and deal with this if need be).
Thanks Professor Giles for your helpful explanation, sometimes it's better to understand these issues, using of examples like this. However, I still have some issues to resolve: 1) you said that the proportion of the way through the sample that the break occurs is λ = 0.44 in this case; to my understanding the sample has 65 observations, so λ should be 35/64=0.55, am I wrong? 2) which values should I use as scalar traceL and
ReplyDeletescalar traceC? Best regards Luis
Dear Professor Giles, thank you for your explanation. I have some issues with the critical values since I would like to know which values are used for scalar traceL and scalar TraceC. In my case, I have 3 variables, 144 observations and I am considering 2 breaks. One in observation 57 and another in observation 80. From the output of the programming I obtain Critical values from (p-r) which in this case is 2. I was under the impression that if the CV is bigger than the stat value then we reject the null hypothesis so in this case is not the same? Any light on this question will be highly appreciated.
ReplyDeleteBest Wishes
Blanca
You always reject if the calculated value of the test statistic exceeds the critical value.
DeleteThank you Professor
ReplyDeleteDear Prof.,
ReplyDeleteWhat if my variable of interest is insignificant in Johansen test?
Which variable are you referring to?
DeleteThank you Professor. I am studying the long-run impact of oil prices on the exchange rate. The dependent variable is exchange rate while my variable of interest is oil price. The normalized equation from Johansen test produced expected signs of the explanatory variables and are all significant except the price of oil (which is the variable i am interested in). The model passes all diagnostic tests. What should I do?
DeleteYou seem to be a little confused between TESTING for cointegration, and MODELLING the data. Do you have cointegration or not? If not, then the equation you mention isn't really relevant. In any event, I would have thought you would be more interested in the short-run dynamics of the relationship, rather than just the long-run relationship. If you DO have cointegration, then you should be fitting an ECM.
DeleteAlternatively, are you sure that your data are all I(1)? If not, then you might consider an ARDL model.
Dear Mr. Giles,
ReplyDeleteThank you for the wonderful blog. Is it advisable to go for Johansen test when the VAR residuals are non-normal? Is there a better alternative or modification to Johansen test in this regard ?
Akshat - see the comments associated with this earlier post: http://davegiles.blogspot.ca/2012/03/overview-of-var-modelling.html
DeleteProf Giles,
ReplyDeleteI have created the CV for my own dataset. However, te results of the Hl(r) cointegration tests are somewhat weird.
The CV for Hl(r) are for Zero coint eq 55.419, at most one coint eq 80.082 and at most two coint eq 55.419. Is it possible to have these types of CV values that go up and down? Any light on this matter will be highly appreciated
No - there is something wrong with what you have done.
DeleteMany thanks, Prof. Giles for the helpful comments and examples! I have one question - currently I am performing a cointegrtion analysis on economic time series. Could you, please, give your opinion about using GRETL software for this purpose. Thank you!
ReplyDeleteGretl is a terrific package and I've blogged about it several times. I'd certainly recommend it for cointegration analysis.
DeleteWhen both trend variables are restricted the results are r=0 47.72468 and r<=1 21.76171?
ReplyDeleteThanks! Your blog is very helpful!
Dear Prof. Giles,
ReplyDeleteThank you for all the help and explaining in simple examples.
I am using EViews and I am confused my variables are I(1). So when i estimate the VECM, I add the variables d(log(x)) or log(x)? (I think EViews difference it once automatically!!!)
I appreciate your help.
Regards
Yasmine
Yasmine - log(x), I believe.
DeleteDear Prof. Giles,
ReplyDeletein Perron, P. (1989) there are critical values for only some values of λ. If possible,could You please point to a paper where full values for models A and C could be seen?
Thank you very much
Those ones (and the corrections in the Perron-Vogelsang paper) are the only ones I'm aware of.
DeleteHello Prof. Giles,
ReplyDeleteYour blogs and codes are indeed very useful. I got a question regarding the structural break point.
Which model is used to identify the structural break point in this case? If you have a blog/codes related to it, kindly guide.
Thanks in anticipation
Hello Prof. Giles,
ReplyDeleteThank you for your post and I find it very useful for me as a research student. However, Iam a little bit confused about your interpretation of Modified ADF test. As it is mentioned that "Clearly, we cannot reject the null of a unit root for either series", I thought that the series are both I(0) when we allow for structural breaks in the unit root test, but it seems that you concluded that they are both I(1).
Also, I will like to understand how the value of λ and the critical values of -3.92 and -3.62 are obtained.
Thank you once again for this blog
The statement is actually correct. Even with the structural break, the modified ADF test has I(1) as the null hypothesis and I(0) as the alternative hypothesis. We reject the null only if the test statistic is more negative than the critical value. The critical values that are cited come from the Perron and Vogelsang "erratum" to Perron's original, as linked in the blog post. The Lambda values come from looking at the series and asking "what proportion of the way through the series does the break appear to occur"?
DeleteThe statement is actually correct. Even with the structural break, the modified ADF test has I(1) as the null hypothesis and I(0) as the alternative hypothesis. We reject the null only if the test statistic is more negative than the critical value. The critical values that are cited come from the Perron and Vogelsang "erratum" to Perron's original, as linked in the blog post. The Lambda values come from looking at the series and asking "what proportion of the way through the series does the break appear to occur"?
DeleteDear Prof. Giles,
ReplyDeleteOne of the best blogs on econometrics in the world. A very student friendly!
However, I have a query regarding the eviews program file. On the code page it is mentioned
"EDIT THE NEXT 2 LINES IF P-VALUES ARE REQUIRED"
scalar traceL=123.6
scalar traceC=114.7
How do we come up with these values?
Also, can the test be performed in eviews if there are two breaks in a series?
Please throw some light.
Thanks in advance!
traceL is the value of Hl(r) statistic
DeletetraceC is value of Hc(r) statistic
Yes - if you look at the code it allows for either one or two breaks .Setting q=3 means 3 regimes, and hence 2 breaks.
Hello Prof. Dave Giles.
ReplyDeleteIs there a guideline for Cointegration test, if only the dependent variable contains a structural break?
The same procedure applies.
DeleteDear Prof. Giles,
ReplyDeleteI have one clarification. If I am using a two endogenous break unit root test and find breaks only in the intercept (i.e. Model A). Does the same procedure applies or do I need to modify the dummies. Please help.
Thanks!
You will need to modify the dummy variables.
DeleteProf, could you please give a small hint on how to do that. Will be of great help.
DeleteThanks!
I am sorry, I meant you have entered dummies as Unrestricted variables!!
ReplyDeleteYes, unrestricted - they are shifting just the intercept.
DeleteDoes this same model apply when interaction dummies are added? Should they be added as exogenous variables?
ReplyDeleteLilian - good question. Yes - add them as exogenous variables.
DeleteHi Prof. Giles,
ReplyDeleteI am performing Johansen Cointegration test on my time series data set. The problem is I am getting an error prompt on Stata ''the sample has gaps r(498)'' . What does this mean and what can be done about it ? Also note that my data set does not contain any missing data however on taking the first difference of the variables,some data seem to be missing.
Thanking you in anticipation .
I don't use Stata (unless I absolutely have to!) There are lots of Stata user groups out there where you can go for help. Good luck!
DeleteDear Professor,
ReplyDeleteI have question regarding to setting up the VAR model. You write that we need to add the next variables:
1. (Linear) trend
2. D2,t-k (where k, the maximum lag length, is 2 in our case)
3. Trend*D2,t-k
4. I2,t ; I2,t-1; ......; I2,(t-(k-1); where again, k = 2 in our case.
However, if we look at your Eviews file, we see that you added only the three last variables: D2(-2) T*D2(-2) I2 I2(-1). So, you did not add the trend in the beginning.
Should it look like T D2(-2) T*D2(-2) I2 I2(-1) ?
Best regards and many thanks for this post,
Stefan
Stefan - yes - thanks for spotting this.
DeleteDave
Dave,
ReplyDeleteOne question. If two series are I(1) but only one of them has a structural break, can we still use this methodology? Thanks
Yes, you can.
ReplyDeleteThanks you so much!
DeleteDear professor Giles,
ReplyDeleteAfter the Cointegration test, I need to set up the final VECM model including these dummies, right?
Kind regards,
Reynaldo Senra
Reynaldo - yes,
DeleteDave Giles
Dear professor,
ReplyDeleteSorry for writing this, but after running your code I got a table like this,
P_MINUS_R CRIT_HL_90 CRIT_HL_95 CRIT_HL_99
1 20.94518 23.50003 28.80999
2 42.04003 45.37806 52.09231
I don't understand this output. In the first column, Is 1 the number of cointegration vectors? I mean, If my test statistics is 30 I can say that there is only one cointegration vector because its value is larger than the value of all the critical values. On the other hand, I cannot say that there are 2 cointegration vectors because my test statistics is 30 with is lower than 42.04003 (which is the the value for the 10% significance level).
Am I right?
Finally, for the decision about the cointegration in my data, I just need to take the test statistics resulting of applying to my data the trace test in any software (including in my data the dummies accounting for the breaks, logically)?
Kind regards and very much thank you for your great blog.
Thanks for your query. Have you read the "read_me" text object in the workfile I supplied, and the comments embedded in the program file? In the latter you will see the comment
Delete' r = cointegrating rank
' p = no. of variables in system
The first column in the output is (p - r), not the cointegrating rank itself.
I presume that you have modified the code in the program file to match your particular situation, as mentioned in the various comments? The table that you supplied relates only to the H(L) test. The main table of results that you should get has additional columns, to the right, for the critical values for the H(R) test.
Regarding your second question, the answer is "yes". I hope this helps.
I am currently doing a VECM exercise where I am using four macroeconomic variables (New home sales, median price of new home sales, 30y mortgage rate, disposable personal income) from 1990-2018, where all 4 four variables have different multiple structural breaks during their history (for e.g for new home sales: two structural breaks one at 2008 and other at end of 2008).
ReplyDeleteDoes the methodology and code you have provided could be applicable to this case: i.e 4 variables with multiple structural breaks.
Yes, the methodology applies. The code allows for 2 or 3 structural breaks. You'd need to modify the code to allow for 4 variables.
DeleteDear Dave,
ReplyDeleteI hope all is well and thank for the great blog.
I am currently testing for unit root with two structural breaks for a sample from 1969-2017; one at 1975 and other at 2004.
How do you get the values for the t critical values when we have two structural breaks?
Thank you,
Hassan
Hassan - I suggest you first take a look at section 4 of this survey paper - https://pdfs.semanticscholar.org/d622/9def1c7c6300ef559b3cf54caeb15b327adb.pdf
DeleteThe test that would probably best suit your needs is developed in this paper:
Junsoo Lee and Mark C. Strazicich, 2003. Minimum Lagrange multipler unit root test with twp structural breaks. Review of Economics and Statistics, 85(4), 1082-1089.
Their test is easy to apply in practice, and their paper includes some tables of critical values.
Prof Giles,
ReplyDeleteThank you for this helpful example.
I have a question about lag selection, if you don't mind me asking.
1-When selecting lag order for cointegration, should we estimate VAR in levels or difference? I assume in levels since cointegration is in levels. Is that correct professor?
And if VAR shows lag order as 1, should we run cointegration with 1 1 lags and accordingly EVCM with 0 0 lag?
2-When selecting the lag order for cointegration, Eviews asks to specify the number of lags to include. The default is 2 and AIC shows 2 as the optimal lag order.5 but when i increase it to 4 or 5, AIC and other criteria show 4 or 5 as optimal.
Having a small sample of 38 observations, what do you think is the best thing to do?
I'd really appreciate your answer!!
Amir,
Amir: 1. Yes, and yes.
Delete2. Go with the longer lag (not 2).