This post is all about estimating regression models by the method of Maximum Likelihood, using EViews. It's based on a lab. class from one of my grad. econometrics courses.
We don't go through all of the material below in class - PART 3 is left as an exercise for the students to pursue in their own time.
We don't go through all of the material below in class - PART 3 is left as an exercise for the students to pursue in their own time.
The purpose of this lab. exercise is to help the students to learn how to use EViews to estimate the parameters of a regression model by Maximum Likelihood, when the model is of some non-standard type. Specifically, find lout how to estimate models of types that are not “built in” as a standard option in EViews. This involves setting up the log-likelihood function for the model, based on the assumption of independent observations; and then maximizing this function numerically with respect to the unknown parameters.
First, to introduce the concepts and commands that are involved, we consider the standard
linear multiple regression model with normal errors, for which we know that the MLE of the coefficient vector is just the same as the OLS estimator. This will give us a “bench-mark” against which to check our understanding of what is going on. Then we can move on to some more general models.
PART 1
Suppose that we have a linear multiple regression model, satisfying all of the usual
assumptions:
 where the regressors are non-random. The MLE for the coefficient vector is
where the regressors are non-random. The MLE for the coefficient vector is

and the MLE for the variance of the error term is

Now, we can open the EViews workfile, and estimate a linear regression model, with Y as the dependent variable, and an intercept and X as the two regressors:
 So, our simple regression model is:
So, our simple regression model is:

 Given the assumed independence of the data, to get the joint data density, and hence the likelihood function, we need to multiply each of the n marginal data densities together:
Given the assumed independence of the data, to get the joint data density, and hence the likelihood function, we need to multiply each of the n marginal data densities together:
 So, to get the log-likelihood function, we need to add the logarithms of the marginal data densities:
So, to get the log-likelihood function, we need to add the logarithms of the marginal data densities:
 We can see that a typical term that will appear in the expression for the log-likelihood function is of the form:
We can see that a typical term that will appear in the expression for the log-likelihood function is of the form:
 To get EViews to perform MLE, we have to supply a typical term of the form (3). This is done via the so-called “LOGL” object. In your workfile, click on the "Object" button, and choose the “New Object” option. Then, highlight "LogL" as, shown below. You can supply a name for this object, either now, or later on when you save it – it may be a good idea to call this new object LOGL01 at this stage.
To get EViews to perform MLE, we have to supply a typical term of the form (3). This is done via the so-called “LOGL” object. In your workfile, click on the "Object" button, and choose the “New Object” option. Then, highlight "LogL" as, shown below. You can supply a name for this object, either now, or later on when you save it – it may be a good idea to call this new object LOGL01 at this stage.

When you click "OK", this is what you see next:

You can now enter the information for the ith term in the log-likelihood function:
@logl LL1
eps = y - c(1) - c(2)*x
LL1 = -log(c(3)) - (eps^2)/(2*c(3)^2) - 0.5*log(2*3.14159)
The first line of code declares that we are constructing a log-likelihood function, and are going to call it LL1. (You can use any name you like.) The second line of code is introduced merely to make the expression in the third line a little simpler. Note that we are supplying the expression for just a single log-density. EViews will assume that the data are independent, and do the summing that we see in equation (2) above for us. Here, the coefficients c(1), c(2) and c(3) correspond to β1, β2, and σ respectively.
The object box will now look like this:

Next, press the "Estimate" button, and this is what you'll see:

Notice that you have a choice of algorithms for maximizing the Log-Likelihood Function. In evaluating the derivatives you should always choose “accuracy” over “speed”. The following results then emerge when you click “OK”:



PART 2
Suppose that instead of assuming Normally distributed errors, you want to allow for “fat tails” (i.e., a higher probability of outliers) in the error distribution. Recall that the Student-t distribution has a density function with this property if the associated degrees of freedom are relatively small. The need to allow for fatter tails in the density may arise, for example, when modelling financial returns. The Student-t distribution has a finite first moment only if ν > 1, where ν is the degrees of freedom parameter. It has a finite second moment only if ν > 2, so probably the smallest value for the degrees of freedom that we should consider is ν = 3.
 You probably know that if the errors of our standard multiple linear regression model follow a multivariate Student-t distribution, then the MLE for the coefficient vector is just the OLS estimator. However, this result does not arise if the individual errors are independent Student-t distributed! This is the specification that we'll follow next.
&
You probably know that if the errors of our standard multiple linear regression model follow a multivariate Student-t distribution, then the MLE for the coefficient vector is just the OLS estimator. However, this result does not arise if the individual errors are independent Student-t distributed! This is the specification that we'll follow next.
&






 where α1 and α2 are unknown parameters, and z is another variable for which data are available.
where α1 and α2 are unknown parameters, and z is another variable for which data are available.
Note that the special case of homoskedastic errors arises if α2 = 0. If we equate this variance
expression with the Student-t variance given above, we obtain:
 or,
or,
 Now we can create a new object, and name it LOGL03. We can use the following code to set up the Log-Likelihood Function for our simple regression model with independent but heteroskedastic Student-t errors:
Now we can create a new object, and name it LOGL03. We can use the following code to set up the Log-Likelihood Function for our simple regression model with independent but heteroskedastic Student-t errors:
@logl LL3
eps = y-c(1)-c(2)*x
v=3
h=v/((v-2)*@exp(c(3)+c(4)*z))
const=@gamma((v+1)/2)/(@sqrt(v*3.14159)*@gamma(v/2))
LL3 = log(const)+0.5*log(h)-((v+1)/2)*log(1+h*(eps^2/v))
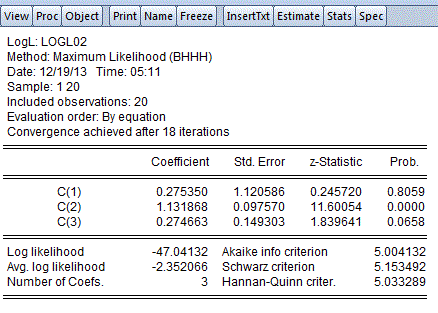
This yields the following MLE output:

The parameter c(4) corresponds to α2. From the associated z-statistic, we see that we can't reject the hypothesis that α2 = 0. So, we'd conclude that in fact the errors are homoskedastic, rather than being heteroskedastic of this particular form.
As in many econometrics packages, the estimation of non-standard models by the method of Maximum Likelihood is quite straightforward. It's always important to check the gradients (and the values of the Log-Likelihood function), using different in initial values for the estimation algorithm, to ensure that you've globally maximized the likelihood. This can be tricky in models with a lot of parameters.
Finally, although this example used a very small sample, it's also important to keep in mind that the desirable properties of Maximum Likelihood estimation - such as consistency and asymptotic efficiency - require a large sample size.
Have fun!
PART 1
Suppose that we have a linear multiple regression model, satisfying all of the usual
assumptions:
and the MLE for the variance of the error term is
Now, we can open the EViews workfile, and estimate a linear regression model, with Y as the dependent variable, and an intercept and X as the two regressors:
and the marginal data density for the ith observation is:
When you click "OK", this is what you see next:
You can now enter the information for the ith term in the log-likelihood function:
@logl LL1
eps = y - c(1) - c(2)*x
LL1 = -log(c(3)) - (eps^2)/(2*c(3)^2) - 0.5*log(2*3.14159)
The first line of code declares that we are constructing a log-likelihood function, and are going to call it LL1. (You can use any name you like.) The second line of code is introduced merely to make the expression in the third line a little simpler. Note that we are supplying the expression for just a single log-density. EViews will assume that the data are independent, and do the summing that we see in equation (2) above for us. Here, the coefficients c(1), c(2) and c(3) correspond to β1, β2, and σ respectively.
The object box will now look like this:
Next, press the "Estimate" button, and this is what you'll see:
Notice that you have a choice of algorithms for maximizing the Log-Likelihood Function. In evaluating the derivatives you should always choose “accuracy” over “speed”. The following results then emerge when you click “OK”:
The OLS results you saved as EQ01 were as follows:
Why is the estimate of c(3) in the MLE output different from the “standard error of regression” in the OLS output? Why are the standard errors different? You should be able to verify that everything has actually been calculated correctly.
Notice that the “Log likelihood” values are the same in each output – this is the value of the Log-Likelihood Function when the MLE’s for the parameters are substituted into equation for the Log-Likelihood given earlier. It is the maximized value of the Log-Likelihood Function.
We need to check that the Log-Likelihood Function has been properly maximized. In the LOGL01 output box, click on “View”, “Gradients”, then “Summary”, to get:
The gradients in each direction of the parameter space are evaluated at each point in the sample. These values are summarized by taking the mean and sum of each gradient across the sample values. We see that the gradients are essentially zero, as they should be.
Note:
- In practice, you may need to edit the elements of the coefficient vector before you estimate a model by MLE to make sure that you don’t silly starting values for the maximization algorithm. For example, in this exercise, if we had not already altered the coefficient values by running the initial OLS regression, we would have had to make sure that c(3) did not start of with the (default) value of zero – can you see why?
- If you need to modify the code for the Log-Likelihood specification in the LOGL01 object box, just select “View”, then “Likelihood Specification” in that box’s header bar, and then edit accordingly.
Now we're ready to estimate a non-standard model by MLE.
Suppose that instead of assuming Normally distributed errors, you want to allow for “fat tails” (i.e., a higher probability of outliers) in the error distribution. Recall that the Student-t distribution has a density function with this property if the associated degrees of freedom are relatively small. The need to allow for fatter tails in the density may arise, for example, when modelling financial returns. The Student-t distribution has a finite first moment only if ν > 1, where ν is the degrees of freedom parameter. It has a finite second moment only if ν > 2, so probably the smallest value for the degrees of freedom that we should consider is ν = 3.

To set up the Log-Likelihood function we need to know the formula for the density function for a random variable that is Student-t distributed, with ν degrees of freedom. For a typical value of the error term, this (marginal) density takes the form:
where ‘h’ is a scale parameter and ‘const’ is the normalizing constant that ensures that the density is “proper” – that is, that it integrates to unity. (In the case of the normal density, this is the role that the (2π)-1/2 term plays.) For the Student-t density, this normalizing constant is:
where the "Gamma function" is defined as
In EViews, we can compute Gamma(x) using the @gamma(x) function.
Using these results, we can again construct the Log-Likelihood function by adding up the logarithms of the marginal data densities:
So, we create a new object and name it (say, LOGL02). Then we use the following code to set up the Log-Likelihood Function for our simple regression model with independent Student-t errors:
@logl LL2
eps = y-c(1)-c(2)*x
v=3
const=@gamma((v+1)/2)/(@sqrt(v*3.14159)*@gamma(v/2))
LL2 = log(const)+0.5*log(c(3))-((v+1)/2)*log(1+c(3)*(eps^2/v))
Estimating the model, as before, we obtain the following MLE output:
A quick check of the "gradient summary" reveals that the estimates correspond to a maximum of the Log-Likelihood function.
Because this model was estimated after the previous one, the stored values for the coefficients are used as the initial values for this estimation. If we edit the coefficient series in the workfile, and set c(1), c(2) and c(3) to "1", this is what we get when we re-estimate the model:
The results (including the maximized Log-Likelihood value) are not affected by the choice of starting values for the maximization algorithm, which is encouraging. Hopefully, we've found the global maximum.
If we compare these results, that assume a model with Student-t errors, with the earlier ones that assumed normally distributed errors, we see that the biggest difference arises with the estimate of c(3). Why is this?
In this last output, c(3) corresponds to the parameter "h", and for the Student-t distribution with v degrees of freedom, the variance is (v /h) / (v - 2), as long as v > 2. So, here, the estimated variance of the errors is approximately 10.922, and the standard deviation is 3.305. In the results based on the assumption of normally distributed errors, c(3) corresponds to the standard deviation of the errors, and the point estimate is 2.413. These two estimates of the standard deviation of the errors are quite similar numerically. In fact, they are not significantly different - note that the standard error for c(3) in the LOGL01 output is 0.603, so a a 95% confidence interval covers the value 3.305.
Recall that as v becomes infinitely large the Student-t density becomes a normal density. So, what do you think will happen if you keep increasing the value assigned to ν in the LOGL02
code? Altering the code so that ν = 300, we get the following results:
You can see that the estimates of c(1) and c(2) now essentially match their counterparts when normal errors are assumed. Going through the calculation for the estimated standard deviation of the Student-t errors we get 2.4163 (compared with 2.4133 for normal errors). This all makes sense.
PART 3
Let’s suppose that we want to generalize our last model even further. As well as allowing for an error distribution with fat tails, let’s suppose that we want to allow for a particular form of heteroskedasticity:
Note that the special case of homoskedastic errors arises if α2 = 0. If we equate this variance
expression with the Student-t variance given above, we obtain:
@logl LL3
eps = y-c(1)-c(2)*x
v=3
h=v/((v-2)*@exp(c(3)+c(4)*z))
const=@gamma((v+1)/2)/(@sqrt(v*3.14159)*@gamma(v/2))
LL3 = log(const)+0.5*log(h)-((v+1)/2)*log(1+h*(eps^2/v))
This yields the following MLE output:
The parameter c(4) corresponds to α2. From the associated z-statistic, we see that we can't reject the hypothesis that α2 = 0. So, we'd conclude that in fact the errors are homoskedastic, rather than being heteroskedastic of this particular form.
As in many econometrics packages, the estimation of non-standard models by the method of Maximum Likelihood is quite straightforward. It's always important to check the gradients (and the values of the Log-Likelihood function), using different in initial values for the estimation algorithm, to ensure that you've globally maximized the likelihood. This can be tricky in models with a lot of parameters.
Finally, although this example used a very small sample, it's also important to keep in mind that the desirable properties of Maximum Likelihood estimation - such as consistency and asymptotic efficiency - require a large sample size.
Have fun!
© 2013, David E. Giles
Dear Prof. Giles,
ReplyDeleteIn Part 2, you assume that the degrees of freedom parameter v is known. Instead, if we assume that this parameter is unknown, then what should be the estimation approach? As I recall, the estimation of this parameter along with the other pertinent parameters by the maximum likelihood method is not straightforward. The loglikelihood function may be ill-behaved for certain parameters values such that the parameter estimates may correspond to local maxima rather than to global maxima. A post on the use of the maximum likelihood methods for Student-t regression models with unknown degrees of freedom parameter will be helpful. Thank you.
Thanks for the comment - I'll see what I can do.
ReplyDeleteSee the follow-up post at http://davegiles.blogspot.ca/2013/12/more-on-student-t-regression-models.html
ReplyDeletedear dave i want to know how to do ml estimation in eviews but some of the screen shots that you have pasted in your blog appear to be broken. kindly resolve the issue if its from your side.
ReplyDeleteNo - all of the screen shots are just fine.
DeleteHow come when I try to recreate this estimation I get the error "missing values in @logl series at current coefficients at observation 1" ?
ReplyDeleteTry different starting values for the coefficients.
DeleteDear Giles!
ReplyDeleteI am getting the missing values in logl I am trying to do the MLE procedure you have performed for 2 variables with 3 variables while using c(3) for the 2nd independent variable or 3rd variable and c(4) in the 3rd line. Can you help me in fixing this problem ?
Probably poor starting values. Edit "c". Don't use zeroes as the starting values.
Deletedear professor Giles
ReplyDeleteI want to know that our data should be stationary for ML estimation method and what are the diagnosis tests after estimation.furthermore how we can compare two model which are estimated by ML method and choose the better one.thanks
Yes, the data should be stationary. You can rank competing non-nested models using any of the information criteria - e.g., AIC, BIC.
Deletethanks for your answer.there is another question.should we check for heteroskedasticity and serial correlation after estimating ml.?if the answer is yes then how should we conduct the tests in logl object?
ReplyDeleteYou should test beforehand, and if it's a problem you allow for this in the construction of the likelihood function.
Deletedear professor giles
ReplyDeleteis that possible to calculate durbin-watson statistic in a logl object?
Why would you want to do that? The DW test is valid only if you are estimating a linear model by OLS, with no endogenous regressors, and with an intercept in the model. Once you have used a LOGL object to estimate your model you can will have the residuals series, and there are plenty of valid tests for serial independence that you could then construct. These will be valid only asymptotically, but that's also true of your MLE, in general.
Deleteso how can I construct those kind of tests?do you mean AC, PAC and Q-Stat in correlogram?
ReplyDeleteOpen the residuals series and click on the "VIEW" tab. You can then get the correlogram immediately. For various tests, use the "trick" described here: http://davegiles.blogspot.ca/2012/02/trick-with-regression-residuals.html
Deletethanks , it was really helpful.
ReplyDeleteDear Dave,
ReplyDeleteI wants to estimate AR-GARCH(1,1) model for a sample of 3388 obs. I write the following codes for this purpose
@logl LL3
eps = y-c(1)-c(2)*y(-1)
h=c(3)+c(4)*eps(-1)+c(5)*h(-1)
LL3 = -0.5*(log(h)+eps^2/h)
When I press estimate the error is "missing values in @logl series at current coefficients at observation 3"
I change the initial values of coefficient in "C" but same problem.
please help me in this regards
Irfan Malik
Ifran - when you estimate, in the box that comes up, make sure you set the sample to start at obs. 3
DeleteDear Sir, I set the sample starts from 3 to end but problem is still there. Is there any problem with codes?
ReplyDeleteIrfan
It's not the code - you will need to create a series, h, in your workfile, with zero values for the full sample, beginning at obs 1, before you run the @logl.
DeleteIf you email me directly at dgiles@uvic.ca I can send you a full example.
Dear Professor,
ReplyDeleteWhen I tried to run a MLE for a GARCH model with conditional skewness, the estimation results changed anytime I changed the starting values for the coefficients. Although in all cases convergence was achieved. Could you please help explain to me, and how can I know which is the most reliable estimation.
Thank you very much,
Lan
Look at the (maximized) log-likelihood values that are reported in each case. Which one is highest?
DeleteDear Professor,
ReplyDeleteI am trying to estimate an ARMA model using MLE. I am having a hard time since the eps series requires its own past values and it won't run. Is it possible to estimate an ARMA model using logl object in eviews? And how could I fix this problem if it is possible?
Thank you very much,
Renie
Renie - you don't need to use a LOGL object. I am assuming you are using EViews 9. Just specify your equation as if you were going to estimate it by OLS. Indeed, choose OLS as the estimator, but in the "options" tab, select "ML" as the estimator.
DeleteNo, I'm using EViews 8.1. Is there also an available option to use student's t distribution similar to part 2 of your example in EViews 9?
DeleteI think you should check the EViews Forum, at: http://forums.eviews.com/
DeleteSir, I want to know , can I use that method for VAR model?
ReplyDeleteIf your VAR model has normally distributed errors, and you`re estimating it using OLS, then you`re already using MLE.
DeleteThe errors of my VAR model arent normally distributed. I want to make them normally distributed: how can I fix it?
DeleteObviously that depends on what distribution they follow. You could try a log-transformation of the y data.
Deletethank you very much ))) it was very useful. You are a Great teacher!!!
DeleteDear sir, i want to compare two models on the basis of their best best..in one model i have used cash flow as predictor of dividend along with some control variables and in another model i have used earnings as predictor of dividend along with control variables. i want to test that which one variable among cash flow and earning is the best predictor of dividend. kindly guide me that what is the suitable statistical test should i used. thanks
ReplyDeleteAs long as your dependent variable is the same in each case you rank the models using AIC or SIC (see my other posts on this topic). Note - this is not a test, just a ranking procedure.
Delete