My previous posts relating to ARDL models (here and here) have drawn a lot of hits. So, it's great to see that EViews 9 (now in Beta release - see the details here) incorporates an ARDL modelling option, together with the associated "bounds testing".
This is a great feature, and I just know that it's going to be a "winner" for EViews.
It certainly deserves a post, so here goes!
First, it's important to note that although there was previously an EViews "add-in" for ARDL models (see here and here), this was quite limited in its capabilities. What's now available is a full-blown ARDL estimation option, together with bounds testing and an analysis of the long-run relationship between the variables being modelled.
Here, I'll take you through another example of ARDL modelling - this one involves the relationship between the retail price of gasoline, and the price of crude oil. More specifically, the crude oil price is for Canadian Par at Edmonton; and the gasoline price is that for the Canadian city of Vancouver. Although crude oil prices are recorded daily, the gasoline prices are available only weekly. So, the price data that we'll use are weekly (end-of-week), for the 4 January 2000 to 16 July 2013, inclusive.
The oil prices are measured in Candian dollars per cubic meter. The gasoline prices are in Canadian cents per litre, and they exclude taxes. Here's a plot of the raw data:
This is a great feature, and I just know that it's going to be a "winner" for EViews.
It certainly deserves a post, so here goes!
First, it's important to note that although there was previously an EViews "add-in" for ARDL models (see here and here), this was quite limited in its capabilities. What's now available is a full-blown ARDL estimation option, together with bounds testing and an analysis of the long-run relationship between the variables being modelled.
Here, I'll take you through another example of ARDL modelling - this one involves the relationship between the retail price of gasoline, and the price of crude oil. More specifically, the crude oil price is for Canadian Par at Edmonton; and the gasoline price is that for the Canadian city of Vancouver. Although crude oil prices are recorded daily, the gasoline prices are available only weekly. So, the price data that we'll use are weekly (end-of-week), for the 4 January 2000 to 16 July 2013, inclusive.
The oil prices are measured in Candian dollars per cubic meter. The gasoline prices are in Canadian cents per litre, and they exclude taxes. Here's a plot of the raw data:

I'm going to work with the logarithms of the data: LOG_CRUDE and LOG_GAS. There's still a clear structural break in the data for both of these series. Specifically there's a structural break that occurs over the weeks ended 8 July 2008 to 30 December 2008 inclusive. I've constructed a dummy variable, BREAK, that takes the value one for these observations, and zero everywhere else.
The break doesn't occur at just a single point in time. Instead, there's a change in the level and trend of the data that evolves over several periods. We call this an "innovational outlier", and in testing the two time series for unit roots, I've taken this into account.
The break doesn't occur at just a single point in time. Instead, there's a change in the level and trend of the data that evolves over several periods. We call this an "innovational outlier", and in testing the two time series for unit roots, I've taken this into account.
In a recent post I discussed the new "Breakpoint Unit Root Test" options that are available in EViews 9. They're perfectly suited for our current situation. Here's how I've implemented the appropriate test of a unit root in the case of the LOG_CRUDE series:

The result is:
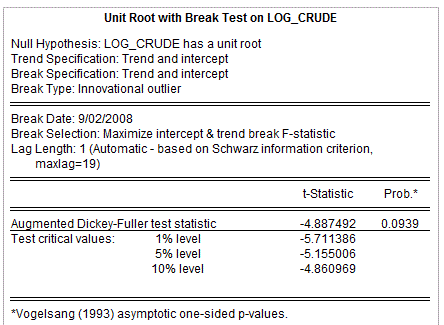
We wouldn't reject the hypothesis of a unit root at the 5% significance level, and the result is marginal at the 10% level. The corresponding result for the LOG_GAS series is:

In this case we'd reject the null hypothesis of a unit root at the 5% significance level, but not at the 1% level. Overall, the results are somewhat inconclusive, and this is precisely the situation that ARDL modelling and bounds testing is designed for. Applying the unit root tests to the first-differences of each series leads to a very clear rejection of the hypothesis that the data are I(2), which is important for the legitimate application of the bounds test below.
Now, let's go ahead with the specification and estimation of a basic ARDL model that explains the retail price of gasoline in terms of past values of that price, as well as the current and past values of the price of crude oil. We can do this in the same way that we'd estimate any equation in EViews, but we select the "Estimation Method" to be "ARDL" (see below):

Notice that I've set the maximum number of lags for both the dependent variable and the principal regressor to be 8. This means that 72 different model specifications will be considered, allowing for the fact that the current value of LOG_CRUDE can be considered as a regressor. Also, notice that I've included the BREAK dummy variable, as well as an intercept and linear trend as (fixed) regressors. (That is, they won't be lagged.)
Using the OPTIONS tab, let's select the Schwarz criterion (SC) as the basis for determining the lag orders for the regressors:

The model which minimizes SC will be chosen. This results in a rather parsimonious model specification, as you can see:

I mentioned in an earlier post on Information Criteria that SC tends to select a simpler model specification than some other information criteria. So, instead of SC, I'm going to use Akaike's Information Criterion (AIC) for selecting the lag structure in the ARDL model. There's a risk of "over-fitting" the model, but I definitely don't want to under-fit it. Here's what we get:

It's important that the errors of this model are serially independent - if not, the parameter estimates won't be consistent (because of the lagged values of the dependent variable that appear as regressors in the model. To that end, we can use the VIEW tab to choose, RESIDUAL DIAGNOSTICS; CORRELOGRAM - Q-STATISTICS, and this gives us the following results:

The p-values are only approximate, but they strongly suggest that there is no evidence of autocorrelation in the model's residuals. This is good news!
Now, recall that, in total, 72 ARDL model specifications were considered. Although an ARDL(4,2) was finally selected, we can also see how well some other specifications performed in terms of minimizing AIC. Selecting the VIEW tab in the regression output, and then choosing MODEL SELECTION SUMMARY; CRITERIA GRAPH from the drop-down, we see the "Top Twenty" results:

(You can get the full summary of the AIC, SC, Hannan-Quinn, and adjusted R2 statistics for all 72 model specifications if you select CRITERIA TABLE, rather than CRITERIA GRAPH.)
One of the main purposes of estimating an ARDL model is to use it as the basis for applying the "Bounds Test". This test is discussed in detail in one of my earlier posts. The null hypothesis is that there is no long-run relationship between the variables - in this case, LOG_CRUDE and LOG_GAS.
In the estimation results, if we select the VIEW tab, and then from the drop-down menu choose COEFFICIENT DIAGNOSTICS; BOUNDS TEST, this is what we'll get:

We see that the F-statistic for the Bounds Test is 32.38, and this clearly exceeds even the 1% critical value for the upper bound. Accordingly, we strongly reject the hypothesis of "No Long-Run Relationship".
The output at this point also shows the modified ARDL model that was used to obtain this result. The form that this model takes will be familiar if you've read my earlier post on bounds testing.

In the estimation results for our chosen ARDL model, if we select the VIEW tab, and then from the drop-down menu choose COEFFICIENT DIAGNOSTICS; COINTEGRATION AND LONG RUN FORM, this is what we'll see:

The error-correction coefficient is negative (-0.2028), as required, and is very significant. Importantly, the long-run coefficients from the cointegrating equation are reported, with their standard errors, t-statistics, and p-values:

So, what do we conclude from all of this?
First, not surprisingly, there's a long-run equilibrium relationship between the price of crude oil, and the retail price of gasoline.
Second, there is a relatively quick adjustment in the price of gasoline when the price of crude oil changes. (Recall that the data are observed weekly.)
Third, a 10% change in the price of crude oil will result in a long-run change of 7% in the price of retail gasoline.
Whether or not these responses are symmetric with respect to price increases and price decreases is the subject of some on-going work of mine.
As usual fantastic! The more detailed instructions, the better for this amateur. I enjoy trying to duplicate your steps. Sometimes the code is too complicated however. Thank you. It is very enjoyable to see economic issues of the day analyzed, along with explanations that help one to learn how to replicate the processes. Right now the price of Brent related to world excess supply or deficit supply compared to world demand seems confusing. There seems to be no relationship. Any chance of a post on the relationship of Brent price to the excess or deficit supply When I figure-out how to select a profile other than anonymous.
ReplyDeleteSir, Can we apply ARDL bound testing to analyze two co-integration relations between the same variables (x and y). e.g. X c Y and Y c X.
ReplyDeleteIf X is cointegrated with Y, then Y MUST be cointegrated with X.
DeleteThank you very much for this wonderful blog Prof. Giles! I have questions concerning ARDL(p,q) bounds-testing.
ReplyDeleteAssume I have X-variable(s) which cannot have a unit-root; for instance a dummy-variable for certain events (like macroeconomic shocks) and its lagged values. Can I include this (these) variable(s) in the "ARDL bounds-testing approach"?
Such a dummy-variable, name it SHOCK, would be rather similar to your “BREAK” variable, I guess. The coefficient on D_SHOCK would then pinpoint the short-run effect of the shock and the coefficient on SHOCK would represent the long-run impact of the macroeconomic shock (although SHOCK is I(0) and cannot be cointegrated with Y)? The bounds-test for cointegration would be an F-test on joint significance of the lagged Y and lagged X variables (not including SHOCK)?
Thank you very much again!
That's correct.
DeleteDear Prof. Dave, I have a model with one dummy variable (crisis). This dummy is set from 1997-1999 for crisis (1) and other years (0) for non-crisis. Then, when I run breakpoint unit root test in level, I got different break date for different variables. But when I run it in 1st difference, I got the same break date (1997) for different variables, all variables stationary in 1st difference. So, can I still put this dummy variable using 1997-1999 in the model? or only 1997 ? The problem is, if I put only 1997 as crisis year, the dummy has insignificant coefficient. Thank you
DeleteIf you have the dummy set to for just one period, that's equivalent to just omitting that observation from the model (see my "Dummies for Dummies" post). I haven't seen your model or data, but I would suggest you leave the dummy set for 1997-1999.
DeleteDear Prof.,
DeleteReferring to the last sentence of the January 18, 2015 question, that says 'The bounds-test for cointegration would be an F-test on joint significance of the lagged Y and lagged X variables (not including SHOCK)?', how can we do it in EViews?
Thank you
Select coefficient tests, Wald test.
DeleteAnother excellent post! Thanks for all the information.
ReplyDeleteQuestion - when I downloaded and plotted the data for gas and oil in a scatter, they appeared to have a linear relationship. In some work I'm doing, the variables seem to have an exponential relationship. Something like y = x1 + x1^2 + x2 seems to fit the data much better than y = x1 + x2. Would an ALDR still work in this case? Would I want to include lags of of the x1^2? Would it enter the model a "Fixed Regressor" like "BREAK" in your example?
Unfortunately, I am stuck with Eviews 8 for now. The lag selection tools are making me green with envy.
Thanks sir!
Yes, that's correct on all counts. If you have a legitimate version of EViews 8.1 on your machine, you can download the Beta version of EViews 9 for free from here: http://register1.eviews.com/beta/
Deleteplease sir, can you give an example on how to go through the nonlinear ARDL model
ReplyDeletethat was also my question
Deleteplz sir clear my confusion about F test... can we use Pesaran et al. table for small sample size or will go for Naryan table? plz answer me as soon as possible
ReplyDeletethnx
Naryan table.
DeleteCritical values for ARDL bounds Tests (Narayan, 2004):
Delete"Reformulating Critical Values for the Bounds Fstatistics Approach to Cointegration: An Application to the Tourism Demand Model for Fiji".
http://www.researchgate.net/publication/268048533_Reformulating_Critical_Values_for_the_Bounds_F-_statistics_Approach_to_Cointegration_An_Application_to_the_Tourism_Demand_Model_for_Fiji
Dear Dave
ReplyDeleteThank you ofr all these explanations. Howver, I would to ask you please how we can do short and long run multipliers graphics with Eviews.
Sincerely
You'll have to contact EViews - I don't work for them!
ReplyDeleteIf you have structural breaks you should not use the usual unit root tests (e.g., ADF) without modification.
ReplyDeleteHello Sir.I run ARDL bound test method and find cointegration bw variables. Than I employ short-run and long-run analysis. In the short-run, I found min. in akaike in X(0to-1) =-4,54 rather than X(0to-5) =-4,53. But, there is a normality(JB) problem in the first one. May I choose 0to-5 or ignore the normality problem in the first one. Moreover, I have heteroskedasticity problem in my estimations both bound test, short-run and ECM granger causality tests. Is it a signiicant problem for time series. Thx for interest and help.
ReplyDeleteI would use 0 to -5, and I wouldn't be too worried about teh heteroskedasticity issue.
Deleteappreciation prof.
DeleteThanks for this post, it's really illuminating. However, I would like to know how we can do a causality test in the ARDL framework. Specifically, if Bounds test shows that X and Y are cointegrated, then (we recall from your earlier post that when variables are cointegrated, there would be at least a unidirectional causality between them) how can we do the Granger causality test in Eviews 9?
ReplyDeleteBy estimating a VAR model - not an ARDL model. I have several posts about this.
DeleteI have a model which is not linear...y=c(1)+c(2)*(x^2)+c(3)*(z^2). Can I apply the ARDL method for cointegration in this model ? If yes, how can I transfrom this model in a ARDL model ?
ReplyDeleteYour model is, in fact, linear - linear in the parameters, and that's all that matters. Just re-label X1=X^2, and X2=Z^2, and then proceed in the usual way.
DeleteThank you very much.
DeleteOne more question...What about this model? y=c(1)+c(2)*x*w+c(3)*(z^2) ? Do I re-label x*w as, lets say q, and proceed in the usual way?
DeleteCan I cointegrate a Cobb Douglas function with an ARDL(or with any other method for cointegration), without using its logarithmic form?
ReplyDeleteNo, certainly not exactly. If |x| < 1 you could use the Taylor series approximation for log(1+x), namely, log(1+x) = x - (x^2)/2 + .......... and go from there.
DeleteThis comment has been removed by a blog administrator.
ReplyDeleteDear Sir,
ReplyDeleteMy data seems to have several structural breaks...do I need to correct for those using Bai-Perron...can this be done in eviews 9
EViews 9 includes the Bai-Perron test.
DeleteDear Sir
ReplyDeleteThanks for the reply regarding Bai-Perron test...however I could not find it in eviews9..
1. if you could pls tell the location.
2. I am dealing with interest rate date, on quarterly basis since 1996q1, which is showing immense oscillations over the entire period and is following no set pattern...should this be taken as structural breaks or can be adjusted by only taking time.
3. When I attempted doing without any dummy variables in microfit, it does not pass the CUSUMQ test and suggests to incorporate a dummy variable for cr.
4. For optimal no. of lags in ardl, can we get them from eviews9 via the automatic lag selection criteria and then carry the work in microfit. Similarly suggest the same for the structural break.
In EViews, the HELP tab will give you the information you need to locate and use Bai-Perron.
DeleteKeep up the good work Dave! I just ran the ARDL model using monthly data and obtained results, BUT, my model exhibits serial correlation past the 11th lag. The Q-stats from lag 0-11 are not serially correlated but past that, (12 to lag 36) are serially correlated. I have (1) included dummies (2) ran the top 8 models as selected by AIC (3) even tried using logs..
ReplyDeleteAny thoughts on this? I truly appreciate your help.
Please see my reply to "Anonymous" immediately below. Given what you've tried already, I'd suspect omitted regressors.
DeleteThanks for the post Dave. I'm running the same type of model (ARDL) using monthly data but I cannot seem to get rid of serial correlation appearing after the 11th lag in the Q-stats despite trying different specifications.
ReplyDeleteAny thoughts?
It could be the functional form - logs or levels? The other thing that comes to mind is a mis-specification through the omission of one or more regressors. Are the data seasonally adjusted, or have you included seasonal dummy variables? If the latter, explore if they should be simply additive, or if they should interact with one or more of the regressors. Bottom line - remaining autocorrelation is probably a result of model mis-specification.
DeleteThanks! I'm looking at the relationship between unemployment and oil prices using both logs and levels. I have also used these dummies as regressors: @EXPAND(@MONTH, @DROPFIRST)
ReplyDeleteStill getting Serial correlation after the 11th lag.
What do you think?
This is fun but it can get old :)
It sounds to me as if you are missing some relevant regressors.
DeleteThanks Dave.
DeleteDear Prof,
ReplyDeleteIn ARDL model Is there a way to get impulse response functions from error correction model (not from VECM) with eviews 9 or manually by excel?
Not that I'm aware of, but why not ask on the EViews User Forum at http://forums.eviews.com/ .
DeleteI am so glad to see your power posts. My questions are that after running ARDL cointegration test for a multivariate time series, which method should i use for causality test? is it possible to use ecm-ARDL results to determine causality between variables?
ReplyDeleteMy preference would be to use a VAR model and the MWALD (Toda-Yamamoto test). I have sevseral posts about this that may help.
DeleteDear Prof,
ReplyDeleteHow to check stability diagnostics in ARDL eviews9? I am talking about CUSUM and CUSUM SQUARE
One suggestion: save the residuals from the ARDL. Then regress these residuals just on a constant using OLS and go from there.
DeleteTry this, from the estimated model window, choose View-->stability diagnostic--> recursive estimation
DeleteDear Prof. Dave,
DeleteDoes the stability test (Cusum&Cusum sqr) really matter in the ARDL? What if I don't include it in my analysis, just like what you have explained in this blog? Thank you.
These tests have nothing to do with ARDL modelling and Bounds Testing, per se. With any estimated model you may be concerned about the model's stability - hence the use of such tests.
DeleteDear Prof. Dave, i tried the trick (One suggestion: save the residuals from the ARDL. Then regress these residuals just on a constant using OLS and go from there.). When i regressed resid on c, i find c is insignificant and R_sqr is zero. What to do?
DeleteDear Prof,
ReplyDeleteI have used two softwares Eviews9 and Microfit4.1 for doing bounds test for my trivariate model but in some cases the results were not the same. Which one is reliable? for my sample (1960-2012 yearly) how many lags should i define as max lags number?
You should address the first question to the suppliers of those packages. With your annual sample, I'd try, maybe, 12 years as a maximum and use SIC to determine the preferred lag length. The latter will undoubtedly be much smaller than 12.
Deletefor ARDL cointegration test and having a sample of less than 50 observations (yearly data), which kind of Heteroskedastisity i should use and how many lags i should determine for doing that test?
ReplyDeleteI doubt if het. is an issue with your time-series data, but you could White's test as it applies to a very general class of types of het. Use SIC to determine the lag length.
DeleteSir, you are doing great work. Can you tell me how i can run ARDL approach by using E-views 7.? because through estimation it does not provide ARDL method in Method section. so how i can apply ARDL in E-views 7.
ReplyDeletethank you. i really appreciate your efforts.
See this post: http://davegiles.blogspot.ca/2013/06/ardl-models-part-ii-bounds-tests.html
DeleteAll you need is OLS. There is also an EViews "add-in" for ARDL modeling that will run in EViews 7. See this post: http://davegiles.blogspot.ca/2014/01/an-ardl-add-in-for-eviews.html
Dear Profesor
ReplyDeleteAfter running ARDL bounds tests, Ramsey rest test null hypothesis is not rejected. firstly i do not know how determine number of fitted values for this test secondly by not rejection of this test what should i do?
The number of fitted values is somewhat ad hoc. You can't use just one - usually people use 2, 3, or 4.
DeleteThe Ramsey test is testing if the coefficients of these extra variables are zero, You want them to be. That is, you do not want to reject the null hypothesis. A rejection is signalling mis-specification of the model, either in terms of functional form, or perhaps omitted regressors.
Also, please see http://davegiles.blogspot.ca/2015/06/readers-forum-page.html
Dear Sir,
ReplyDeleteI was wondering if you could have an idea of how to find lag lengths using Gretl package.
Thanks!
Lag lengths for what, exactly?
ReplyDeleteAlso, please see http://davegiles.blogspot.ca/2015/06/readers-forum-page.html
Dear Prof,
DeleteI was asking how to determine optimal p&q while using Gretl package and if possible how to do bounds test.
Thanks for your insights!
Pascal - try combinations of p and q and minimize SIC. To do the bounds test, all you need is access to OLS - see my earlier post on this in this blog.
DeleteAlso, please see http://davegiles.blogspot.ca/2015/06/readers-forum-page.html
Sir your example uses two variables. I wanted to ask that can we replicate the same example using multiple variables. Plus how can we find the causality taking the variables in pairs. . Also please letme know is it necessary to take the value in log for the model? Thanks
ReplyDeleteSidra - yes, you can do the same thing with three or more variables. The causality testing should be done separately in the context of a VAR model. You don't have to take logarithms of the data.
DeleteSir can ARDL model be used of all the variables are I(1) and none is I(0) or I(2) ?
DeleteI have replicated the above example with multiple variables. It is found to have a long run relationship ,but one of my long run coefficients is showing the value 0 (although t statistic is significant) what does this mean and how to interpret it .
DeleteThe equation is
Cointeq = LOG(REAL_PER_CAPITA_INCOME) - (0.0008
*ELEC_PER_CAPITA + 0.0000*TOTAL_LABOUR_FORCE + 1.1345
*GFCF__OF_GDP + 9.6866 )
The dependent variable is taken in log and the others in level.
Many thanks
Looks to me like a scale issue. The value is zero to 4 decimal places, but it's not really zero. Try re-running everything after dividing your TOTAL_LABOUR_FORCE series by (say) 10,000. All this will do is scale (multiply) the estimated coefficient by 10,000. The you'll probably see an effect. No interpretations or other will be affected by doing this, and the t-statistic will be identical to what it is now.
Deletehello , i have dependant var I(0) , 6 independant var are I(1) , 1 independant var is I(0) and one I(2) ,, im confused between VAR and ARDL model , which one is the appropriate?
ReplyDeleteVAR, using Toda-Yamamoto method - see my earlier posts. As I state in this post, you can't use ARDL if you have I(2) data.
DeleteAlso, see http://davegiles.blogspot.ca/2015/06/readers-forum-page.html
Dear Professor
ReplyDeleteAccording to one paper i found Long-run parameters and standard errors estimaed by ARDL method are biased specially in small sample data. That paper suggested using bias-corrected bootstrap method instead of delta method. Now my question is that how is it possible to do this in eviews 9.0?
Yes - but you'd have to write an EViews program to do it.
DeleteAre the bounds F- and t-tests for level relationships still valid in a conditional unrestricted ECM with a linear *and* quadratic trend? And in a more general ARDL?
ReplyDeleteThe tables of critical values given by Pesaran et al. allow for various intercept-linear trend combinations, but they won;t be valid of you have a quadratic trend in the model. If by a "more general ARDL" model you mean one with more than two variables, then yes. The parameter, k, in the Pesaran et al. tables is for the number of "x" variables in the model.
DeleteDear Mr. Dave Giles
ReplyDeleteI have a question. How do I make the Granger causality test? because I have seen it in the papers mentioned always performed test. Another question. Is it necessary to analyze the causality in the short and long term?
Thank you very much for your answer
Regards
Andres
Andres - see these posts:
Deletehttp://davegiles.blogspot.ca/2011/04/testing-for-granger-causality.html
http://davegiles.blogspot.ca/2011/10/var-or-vecm-when-testing-for-granger.html
http://davegiles.blogspot.ca/2012/04/surplus-lag-granger-causality-testing.html
In the case of the model used ARDL
ReplyDeleteWhen the joint integration testing there I find no long-term relationship
Do not I continue to pause, or search for causal between variables
I'd do some causality testing. Here's why.
DeleteIf there HAD BEEN cointegration, then there HAS to be Granger causality one way or the other. If there NO COINTEGRATION, then there may or may not be G-causality. It's worth testing for it.
HELLO,
ReplyDeleteThanks for the great post. However i have a question, is it okay to include a dummy variable to capture a break the data for a long period of time say (20002Q1-2010Q4,if you have justification of an event that is likely to cause such break in the series) 2) when using a VAR (from your ARDL 2 POST) to obtain the lag of the dependent variable, are we to specify the dummy variable as an exogenous variable(in difference and in lagged level) as well? 3) what if i find no cointegration are there any conventional model to test the short run effect as Granger causality test only tells the direction of causality? lastly,(not related to this post) please do you have a post on stochatic simulation method of forecasting or any forecasting related post?i l really look forward to your reply. Thanks very many.
That would be fine if you're really sure that there is just the one break. Keep in mind that the dummy variable is simply shifting the intercept in the model, so this give you the answer to your second question - you would treat the dummy variable in exactly the same way that treat the intercept. So, you would not be differencing/lagging it. If there is no cointegration, then a simple ARDL model (not the sort used for bounds testing) would provide a useful basis for examining short-run effects. For instance, see http://davegiles.blogspot.ca/2013/03/ardl-models-part-i.html . Finally, I don't have any posts on stochastic simulation - why not leave me a request on the "Readers' Forum" page and I'll see what I can do. If you use the "Search" on the blog page (right sidebar) you'll find a handful of posts on forecasting.
Deletehi dave,
ReplyDeleteasthis is the most recent post you get to reply, i have question concerning T-Y granger causality test in your previous post. Does the AR graph really matter? because when i estimated a VAR(4) model selected by the information criteria, there was no problem of Auto correlation but however the on AR graph,few of the points where outside the circle. when i estimated a var(3) all the points where inside but there was a problem on auto correlation...please what do you think is wrong? thanks...~valerie
There are 2 quite different things going on here, One is testing for autocorrelation in the residuals of the model. The other is checking to see if the estimated coefficients of the VAR model imply a dynamically stable autoregressive structure. Unless the inverse roots of the characteristic equation associated with VAR lag structure are all inside the unit circle, the model is dynamically unstable - a shock to the model will just grow and grow. You wouldn't want to use a model with that feature.
Deletethank you.two final questions please. are there any scenario where the specified lag length chosen by the information criteria, does not still remove the problem of autocorrelation?if there is, are we allowed to increase the lag length ourselves? secondly, if the lag length chosen is e.g 7 and which solves the AC problem in the residuals + the AR condition,then estimating the var(7) in which case we include one extra lag (p+m, variables are all I(1)) when specifying the exogenous do we still have to check the AC and AR graph of the new specified model? just wondering. thanks ~ Valerie
ReplyDeleteValerie: Yes, this often happens, perhaps not surprisingly because the IC are looking at the "fit" of the model (with a penalty for complexity), whereas autocorrelation may be arising because of incorrect functional form, etc. If this occurs, you often need to increase the max. lag length that's suggested by the IC. That's OK. The main thing is to be happy with the specification of the "base" model. It sounds as if you are referring to the TY procedure where you then add lags of the variables (but don't include these extra lags in the null hypothesis) when testing for Granger non-causality. Adding them is just a "trick" to ensure that the test statistic you're using has the usual asymptotic distribution. That being so, you don;t have to be so concerned about the AC etc. in the "final" model on which the testing is based.
DeleteDear Professor,
ReplyDeleteIs it not necessary to check that the underlying variables are not I(2) when structural breaks are present?
The ARDL bounds testing requires that no variables be I(2), whether or not there are breaks.
DeleteDear Prof.
ReplyDeleteIf I have, for example, five variables. The null hypothesis of no-cointegration would be H0: α1=α2=α3=α4=α5=0. What is the correct form for the alternative hypothesis of cointegration? Is it
1) (α1≠α2≠α3≠α4≠α5≠0), or
2) At least one the α's is not zero, or
3) α1≠0, α2≠0, α3≠0, α4≠0, α5≠0, or
4) Some other form
Could you also please explain.
Thanks
Sal
Sal - option (2), for reasons given in the original paper.
DeleteDear professor before I estimate the ardl should I have to perform the causality test? if the answer is yes, then how should I proceed if I have some variables that are I(1) and some I(0), because I know can estimate the ardl with different integrated series, but I cannot perform the causality test. Thanks
ReplyDeleteGood Day
ReplyDeleteWith respect to the direction of influence, I am not certain how this should be interpreted. Apart from referring to theory, how should the signs be interpreted out of Eviews9.
My confusion stems from the fact that in Johanson Test result in eviews8 the signs in the cointegration equation were swapped i.e. if they were -ve they were to be interpreted as +ve.
My Eviews9 ARDL results are below
Cointeq = GVT_BONDS – (-0.2733*GDP__ + 0.9637*CPI__ -1.7030
*CA_GDP__ + 0.3897*BD_GDP__ -0.1901*LEADING_INDICATOR
-0.0006*NET_BORROWING + 0.0001*NET_PURCHASES + 20.9160 )
Variable Coefficient Prob.
GDP__ -0.273306 0.2663
CPI__ 0.963655 0.0049
CA_GDP__ -1.702984 0.0042
BD_GDP__ 0.389691 0.2213
LEADING_INDICATOR -0.190125 0.0001
NET_BORROWING -0.000605 0.0027
NET_PURCHASES 0.000053 0.8282
C 20.915959 0.0000
I suggest you address this to the EViews forum.
DeleteDear Prof.
ReplyDeleteLooking at your example of bivariate equation with the same break period, now, If one has a multivariate equation (e.g. having five variables), and each variable has a different break date. Can we include all the break point in our estimation?
Yes, you can.
DeleteThank you Prof. Another question on multivariate equation with different break period. I use test for structural break purposely to further confirm that non of the variable is I(2), after that i did not include dummy for the break period in the regression instead i use CUSUM and CUSUMSQ test to test the overall stability of the parameters, and there are stable within the 5% significance level. Does this procedure appropriate?
DeleteThat seems reasonable.
DeleteThank you Prof.
DeleteThank you very much, Professor, I have a question: I want to measure the impact of the development of the banking sector on economic growth using ARDL model , and I have six variables, you follow the same steps?
ReplyDeleteYes, you do.
DeleteDear Prof. How is insert BREAK a the program EViews 9
ReplyDeleteCreate a dummy variable.
Deleteif we have multiple break for different regressor, for example 1994, 1999, 2001, 2004 for 4 different regressor, is it enough to create 1 dummy variable that include all the break?
DeleteIf you have 4 breaks for the same variable, then this implies 5 different "regimes" and you will need to construct 4 separate dummy variables.
DeleteDear Prof. How should I "Breakpoint Unit Root Test" for six variables?, How is the expression within the form?, Did you see that 35 of the observations adequate ?, variables are:
ReplyDeleteReal gross domestic product per capita variable dependent
Matrix variable banking development
Consumer prices inflation
Government spending ratio GDP
Ratio of capital accumulation to GDP
Trade openness variable
Waiting for your answer, thank you Professor
I don't wish to sound rude, but I just don't have time for this. Sorry!
DeleteDear Sir, Thank you for your helpful post!
ReplyDeleteHow can i get Eviews 9 demo? I’m a student and i have no organization, so i can’t fill the required fields…
How can i solve this problem?
You will need to contact EViews directly - I don;t work for them! :-)
DeleteThank you for this wonderful explanation.
ReplyDeleteFor beginners in ARDL models, like me, it is of great help.
hello Sir, Thank you for providing this valuable post!
ReplyDeleteI want to ask how to test for unit root for single structural break using Philips Perron Root Unit test as well as test for multiple structural break in eviews 9? Does the noted Breakpoint test above already account for this or is there another command I need to use in eviews?
Many thanks and appreciate the help,
Angeline
Angeline - the breakpoint tests in EViews 9 give you all that you need.
DeleteDear Professor Giles,
ReplyDeleteJust wanted to thank you for the blog on ARDL estimation which has helped me a lot. I wanted to ask you a question related to ARDL. I am running three country-growth equations in Eviews 9 and I have 42 observations for each country (1970-2013). However, I am concerned about the number of regressors (both fixed and dynamic) that are being generated from my ARDL growth equations - at least 22 parameters (including both short and long-run coefficients). Can I still proceed with this regression estimation and what would be the effect on degrees of freedom. Or in other words, what is the limit on the number of regressors that I can include with a sample with 42 observations. The regressors that I have included are investment, human capital, population growth, government consumption, real interest rate, real exchange rate, inflation and fixed regressors (dummy variable for multiparty democracy, foreign aid, commodity price and foreign direct investment). In total I have 11 regressors with a sample of 42 annual observations.
I look forward to hearing from you on this important matter Sir.
Obviously, you have enough degrees of freedom to fit the model. However, your degrees of freedom will be limited and your inferences will not be very "sharp".
DeleteSo what should be my cutoff number of regressors to use with a sample of 42 annual observations?
DeleteAs with any regression, there is no "cut off number".
DeleteDear Prof.
ReplyDeleteThank you for your elaborate post. It really helps us. I downloaded your linked Eviews Code but there is some error. It is not opening. Kindly fix it. Thank you.
Thanks _ I realise there is a problem. EViews issued a "patch" to the package so the old code won't run. I'll get to it as soon as I have a chance.
ReplyDeleteHi, dear Prof.
ReplyDeleteI have run ARDL model using eviews 9 and I have got the result. My question
Is how can I check for serial correlation and stability and R square? Thank you
The R-square is reported in the output. As with any OLS regression, click on the "VIEW" tab and you can get RESIDUAL DIAGNOSTICS, and STABILITY DIAGNOSTICS, as usual.
DeleteTHANK YOU FOR REPLY, BUT MY DATA IS PANEL DATA, AND THERE IS NO STABILITY DIAGNOSTIC WHEN WE SELECT RESIDUAL DIAGNOSTIC IN EVIEWS 9, WHAT SHOULD WE DO TO TEST STABILITY OR JUST IGNORE THE TEST? THANK YOU
ReplyDeleteThat's what the CUSUM information is for.
DeleteHi Professor,
ReplyDeleteMy all variables are I(1), not mix of I(0)&I(1). Can I still use ARDL instead of ECM as I get better results using ARDL model.Thank you.Oz
Oz - yes, you certainly can.
DeleteThank you so much for the prompt response.Best Regards
DeleteHi professor,
ReplyDeleteyou said in the last part "Third, a 10% change in the price of crude oil will result in a long-run change of 7% in the price of retail gasoline. "
is it 7% or 70% ?
Thanks
No 7% is correct. A 1% change leads to a 0.7% change, or a 10% change leads to a 7% change.
DeleteSir, can you tell the different correlogram q statistics and lm serial correlation test and which is more important as a test in ARDL estimation.
ReplyDeleteSee this post: http://davegiles.blogspot.ca/2015/05/alternative-tests-for-serial.html
DeleteDear Professor,
ReplyDeleteThank you for your fantastic blog.
In your example you use 2 variables but do we know why EViews reports k=1 (in the bounds testing output)? In the original Pesaran et al. (2001) paper k stands for the number of regressors which in this case is k=2. Also EViews reports the k=1 critical bounds (p. 301 from Pesaran et al., 2001) while should report k=2. Thank you very much.
I suggest you check with the EViews forum at http://forums.eviews.com/viewforum.php?f=18
DeleteDear professor, I really appreciate your very helpful blog on ARDL model. I am running ARDL for my master thesis. However, I did not include the linear trend in the specification (I choose rest. constant), and the results are very reasonable. Today after reading your blog, I tried selecting the linear trend and the results become not statically significant for most of the variables. Can I exclude the trend ? Can you explain why there is a big difference when including and excluding the trend. Is it necessarily include the trend all the time?? Thank you in advance for your support!
ReplyDeleteYou don;t have to include the trend term - if it's insignificant, then by all means drop it.
Deletemany thanks professor for your prompt explanation! Your econometrics blog is amazing!!
DeleteThanks for the good info Prof. My questions, is it necessary to run a LM test for testing and detecting the multicolinearity and heteroskedastcity test before we running the bound test and cointegrating and long run test? or its just enough by looking the Q stats.
ReplyDeleteif there is no long run relationship based on bound test, then what next? are we going to stop there and then give up?
Thanks Prof.
There seems to be some confusion here. There is no LM test for multicollinearity. You could test for homoskedasticity. The Q statistics tell you about the serial independence of the errors - nothing to do with heteroskedasticity.
DeleteThanks for the post. I have a question regarding the modeling. Ex what if I have 10 variables where some are strongly correlated and I want to assess the long/short run relationship with a variable y. Is it possible to split the model into two ardl? one for 5 variables and one for the other 5 and still obtain relevant results? I saw a similar question on stackexchange (no answer) so I though I would ask you.
ReplyDeleteNo, it's not, and the same applies for any regression model.
DeleteDear proof for reporting short term effects do we need vecm model or with eviews9 can we get it from directly ardl model <?
ReplyDeleteYou can ge this straight from the ARDL model.
DeleteFor ardl model can we use non stationary variables? after checked variables stationary levels and if there is no I(2). Which one is better to take diferences and add to non stationary variables after make them stationary or add them to model non stationary
ReplyDeleteYes you can - that's the whole point of the ARDL modelling.
DeleteI wanted to thank you so much for the blog on ARDL estimation which has helped me a lot. I wanted to ask you a question related to ARDL. I am running one country-growth in Eviews 9 and I have 25 observations (1990-2014). However, I have one dependent variable and three independent variables. Can I still proceed with this regression estimation and what would be the effect on degrees of freedom. Or in other words, what is the limit on the number of regressors that I can include with a sample with 25 observations.
ReplyDeleteDegrees of freedom are determined in the same way here as for ANY regression model. With that few observations, it's unlikely that you'll be able to specify an appropriate lag structure.
DeleteDear Sir,
ReplyDeleteThank you very much for your post! It really helps.Could you please explain or show me any papers to read through related these problems?
1- why is heteroskeadasticity not a problem in ARDL model? Or if applicable, is there any ways to deal with this problem?
2- Some people said that when the absolute value of ECT (-1)is larger than 1, it is still acceptable in financial research. Is it true?
I really appreciate your help!!!
Regards,
1. It's not that het. isn't a problem - it's unlikely to be present with time-series data.
Delete2.Nope, it's not true.
Dear Professor,
ReplyDeleteIs it feasible to use growth rates (f.e D(lngdp) or growth rate of exports)as our data to avoid problems related with the order of integration? or maybe because of the difference-nature of some aspects of ARDL techniques our results would be from the point of view of economics non-interpretable?
Socrates
Certainly, that's quite common.
DeleteHi Giles, Thank you for your sound blog at first. I have one question to you. You constructed a dummy variable "break". It's okay. But your break variable in the estimated ARDL model is not statistically significant since P-vaule is 0.0668 > 0.05. Do you disregard/ignore this case? For example, I did similar ARDL model. And I obtained that P-value of Break is 0.3097. Should I continue to use this model with Break? Or should I delete this dummy? Or does there exist a mistake in my case? Thank you for your helps.
ReplyDeleteAs I'm sure yo know, the thing about a p-value is that it's up to you how you interpret it. At what point is it so small that you decide to reject the null hypothesis. My p-value was about 6%, so if I had a 5% significance level in mind I would not reject, but I WOULD reject the null (of a zero coefficient value) at the 10% level. For this reason, I retained the dummy variable. With a p-value as large as yours, I think that most people would not reject the null. That is, they would remove the dummy variable.
DeleteMr Ozcan maybe you are able to retain the dummy in the case that your ARDL model faces stability problems with Cusum tests and the dummy variable ''fixes'' f.e the CUSUM of Squares diagnostic for 5% level. I am not sure if that is legitimate although i have seen it before in papers. What do you think Dr Giles?
DeleteHello! Many thanks for your blog, it is really cool and usefull. Is there a way to check the stationarity and cointegration for abnormal series (large kurtosis)? Many thanks for your answer! Mr. Z.
ReplyDeleteYou can use the ADF test or the KPSS test to test for the stationarity of the data even if the series is non-normal. You should avoid the Johansen procedure for testing for cointegration in this case, but the Engle-Granger 2-step procedure is still valid.
DeleteHello! Many thanks for your blog! Could I use Johansen test with I(1) and I(0) process?
ReplyDeleteThanks
No - all of the series have to be I(1).
DeleteDear professor,
ReplyDeleteThank you very much for your post. I´m running an ARDL for my master thesis, where i have in total 6 variables. I have seen many papers use every variable in turn as dependent variable when testing for cointegration Is that correct? In that case, is it possible to change the specification (constant, constant + trend, none) depending on which variable you have as dependent?
Thank you very much
If you're using an ARDL model, then you've already decided on a dependent variable. There's no reason to try different choices of dependent variable. The literature you're referring to is the Engle-Granger 2-step method of testing for cointegration, and applies only to the case where all of the variables are I(1). In that case, you can choose different variables as the LHS variable in the cointegrating regression, The choice you make can affect the outcome of the test. Usually you would always include an intercept, and if you use a trend variable, you'd use it in every case. If the results depend on the way the regression is normalized, which result do you choose? There's some old evidence (Dolado wet al. as I recall) that suggests that you should choose the normalization (choose the dependent variable in the first-stage cointegrating regression) that maximizes the R-squared. (One of the few situations where maximizing R-squared has any justification!)
DeleteDear Dave, Fede is quite right in saying that many papers use ARDL approach by normalising on each variable in turn. I guess, one should normalise on a variable if the right hand side variables are the forcing variables. Especially literature in energy economics i.e. role of energy in growth is awash with such papers.
Deletedear professor,
ReplyDeletethank you very much for your post i am working with panel data in eviews 9 as i have done with the ardl but please help me whether it is possible to test the ardl bound test for panel data in eviews
There's no "canned" routine for this in EViews so you'll have to write some code. Also, check the EViews forum at eviews.com
DeleteDear Sir,
DeleteI run the ARDL model and face the "singular matrix" error. How can i solve this?
It's just like any other regression model. You're trying to use too many lags relative to the sample size.
DeleteDear Professor Giles,
ReplyDeleteThank you for your fantastic posts !
I have a question regarding the “cointegrating form” of the model. If the coefficient of CointEq(-1) is negative but lower than -1, would the ECM between the two variables of interest still be validated ? Would it mean that there is no “stable” long-run relationships between the two variables?
According to the Engle & Granger and the Johansen methodologies, this coefficient must be negative but higher than -1
Thank you so much for your reply
Kind regards
That's right - if it's more negative than -1 then the adjustement process is "over-correcting".
DeleteDear Professor Giles,
DeleteI have benefited greatly form your blogs. THANK YOU! My question is related to the question above - if my model is great in every aspect (significant and correct signs) but the coefficient of CointEq(-1) is -1.56 (which is over-correcting), what do you think may be happening? What do you mean by "over correcting" and what may be causing it? Can I use that model still or would it be inappropriate to keep that model?
I look forward to your response.
You should not use the model. Almost certainly the maximum lag lengths have been mis-specified.
DeleteDear Professor,
ReplyDeleteThank you for your help in understanding this model, there are not that much information about how to proceed and understand what the results means and what to select.
I just have one question: if you see that the variable LOG_CRUDE has a unit root, why you do the ARDL model without the 1st difference of that serie but with the non-stationary serie? for this model is not requeriment for the series to be stationary? if not, what about spurious correlations?
Thank you so much for your help.
Regards.
That's the whole point about the ARDL bounds testing. You can use a mixture of I(0) and I(1) variables - the "bounds" are for "all I(0)" and "all I(1)" extreme situations.
DeleteDear Professor Giles,
ReplyDeleteThank you for your fantastic posts ! I don't want to use any lag of the dependent variable in my regression (its capturing most of the variations in the model). Is that possible?
Thanks
No, it's not - that will totally invalidate the ARDL/bounds testing procedure.
DeleteDear Dave,
ReplyDeleteare you going to go over the non-linear ARDL? I think this is an important topic that needs your great feedback and great explanation.
thanks Prof, my name is chenny from Indonesia...your ardl tutorialis very clear..its very helpfull...thanks
ReplyDeleteDear Professor,
ReplyDeleteThank you very much for the excellent blog post. This is very useful. I'm testing ARDL for the first time. I got the results for the bounds test and long run coefficients. However I have a question on ECM. According to you error correction coefficient is Coint(-1) taken from the long run form. How can I interpret it?
As in any error-correction model, it tells you the speed of adjustment from a short-run out-of-equilibrium position to the long-run equilibrium
DeleteDear Professor Giles,
ReplyDeleteYour posts have been tremendous help! I found serial correlation and am not sure how to resolve them before going on to Bounds test. Any suggestion, please? Thanks.
Dene - you should be able to resolve this by adding one or more ADDITIONAL lags of the dependent variable you're using in the ARDL model, beyond the max. number suggested by SIC or AIC.
DeleteRespected Sir!If I am facing serial correlation in residual of regression output. What should I do pls?
ReplyDeleteMuhammad Ajmai
You should be able to resolve this by increasing the maximum lag length for the dependent variable.
DeleteDear Professor, Is there a "Breakpoint Unit Root Test" for panel data? In Eviews or else?
ReplyDeleteThis comment has been removed by the author.
DeleteIn Stat you can apply the zandrews or clem commands to individual time-series within a panel. e.g., see http://ageconsearch.umn.edu/bitstream/117499/2/sjart_st0080.pdf
DeleteHEllo Sir,
ReplyDeleteHow do you choose your dependent variable if there are more than two variables in the ARDL model?
Well, an ARDL model is like any other regression model. You're trying to "explain" one of the variables. In my case here it's obvious that I want to see if gasoline prices respond to changes in crude oil prices, so the former is the dependent variable. I wouldn't reasonably expect things to be reversed! Similarly, if I were working with consumption and income, consumption would be the dependent (LHS) variable in the model.
DeleteThis comment has been removed by the author.
ReplyDeleteFaisal no, you can't do this with an ARDL model. You need to use a VAR model with your I(1) variable first-differences, and the other variables in levels. (You can also difference the I(0) variables if you wish.)
DeleteThank you very much Dear Professor!
DeleteHi Dave – You’re doing awesome work
ReplyDeleteQuestion:
I ran the cointegrating and Long run model and obtained an error-correction coefficient of -0.5614 which was negative and significant.
The long run coefficients were not significant. What is the meaning/interpretation of this?
Does it mean that the two series just move together, but one cannot explain the other?
Thanks. Yes, I think that's how I'd interpret that result.
DeleteThanks - that was quick :)
DeleteI really liked the way you had posted your blog. Keep sharing more with us.
ReplyDeletesir Is FMOLS applicable for time-series data: all are I(1)
ReplyDeleteYes, that's what it's designed for, as long as you believe that there is only one cointegrating vector. Otherwise Johansen's methodology should be used.
DeleteDear Professor,
ReplyDeleteShould I apply tests lik serial correlation (Breusch–Godfrey) and heteroskedasticity(ARCH) even after using the HAC(Newey-West) option in Eviews 9?
Thank you
Yes - especially tests for serial correlation. The presence of the latter could signal a mis-specification of the lag length(s). And the bounds test critical values are only valid if the errors are independent,.
DeleteDear Professor,
ReplyDeletementioned below a table from a published article. Is it mandatory for ARDL model to have only ONE co-integration? such tables are reported in research article.
Dependent variable AIC lags F-statistic Decision
FF (F\Y, K, L, T) 2 6.701 Cointegration
FY (Y\L, K, F, T) 2 2.365 No cointegration
FL (L\Y, K, F, T) 1 0.762 No cointegration
FT (T\Y, K, F, L) 1 2.736 No cointegration
FK (K\Y, L, F, T) 1 2.552 No cointegration
Lower-bound critical value at 1% 3.06
Upper-bound critical value at 1% 4.15
Lower and Upper-bound critical values are taken from Pesaran et al. (2001), Table CI(ii) Case II.
Thank you
Take a look at this EViews blog post...... http://blog.eviews.com/2017/05/autoregressive-distributed-lag-ardl_8.html
DeleteWould you please tell me that to Run ARDL, it is necessary that dependent variable is I(1), or it can be I(0) or I(2)? Thanks
ReplyDeleteThe whole point of ARDL modelling and bounds testing is that you can have a mixture of I(0) and I(1) variables. I've stated really clearly, several times, in several posts, that you CAN'T have I(2) variables ion the model.
DeleteGood Day Professor.
ReplyDeleteI estimated an ARDL model of 6 variables. After several attempts (using different lags ) to find a better estimate, i got a selected ARDL model using AIC as (1,1,0,0,1,2) while using SIC is ARDL (1,0,0,0,1,2).
1. Can I still use this model given these lags selection?
2. Which among the AIC and SIC is better?
ARDL (1,1,0,0,1,2) = AIC
ARDL (1,0,0,0,1,2,) = SIC
Thank you sir, in anticipation for your kind acknowledgment
Best regards.
Having "too many" lags is preferable to having "too few". So (in this particular case) I'd go with AIC model.
DeleteDear Prof. Giles,
ReplyDeleteIn the example, the gasoline price is estimated on crude oil price. Does it mean that there is no opposite direction (from gasoline price to crude oil) because ARDL of the first equation assume exogenous independent?
Many thanks for your detailed post about ARDL here.
Yes, that's what's assumed in this example.
Delete