This post is prompted by a question raised by Irfan, one of this blog's readers, in some email correspondence with me a while back.
The question was to do with imposing inequality constraints on the parameter estimates when applying maximum likelihood estimation (MLE). This is something that I always discuss briefly in my graduate econometrics course, and I thought that it might be of interest to a wider audience.
Here's the issue.
Most econometrics/statistics packages that allow you to set up an arbitrary likelihood function, and then maximize it, don't allow you to constrain the signs or magnitudes of the resulting point estimates. For instance, suppose that the likelihood function is L(ψ | y), where ψ is a p-element vector of parameters, and y is the n-element vector of random data. We may have reason to believe that a particular element of ψ, say ψi, should lie between zero and one in value. However, when we obtain the MLE of this parameter, say ψi*, the latter turns out to have the value 1.1.
There are several thoughts that might/should go through your head if this happens. For instance:
- Is my model (and hence the likelihood function) correctly specified?
- MLE is a consistent estimator, but in general it may be biased in small samples. Is my sample size, n, large enough for my results to be "reliable"?
- Even though the point estimate of ψi exceeds one in value, is it significantly greater than one, based on the standard error for ψi*?
- Can I somehow "trick" the optimization routine that's being used to obtain the (unconstrained) MLE, ψ*, into giving me a result such that my estimate lies between zero and one?
I'm not saying that you should respond to the fact that ψi* > 1 by trying to constrain the MLE of the parameter. But you might decide to do so in order to get "economically sensible" results - especially if all else fails.
What you can do is to "re-parameterize" the model, and hence the likelihood function, in order to ensure that the desired constraints are satisfied. Rather than maximizing L(ψ | y), you can introduce a new parameter vector, θ, such that θ = g(ψ), where g(.) is a suitable continuous function. Then you maximize L(θ | y) = L(g(ψ) | y) with respect to ψ, and get the (constrained) estimate of θ as θ* = g(ψ*)
Very importantly, notice that if we are using MLE to estimate φ, this corresponding estimate of θ will also be the MLE - and not just some arbitrary estimator. This follows from the "invariance property" of MLE. (See this recent post.)
What you can do is to "re-parameterize" the model, and hence the likelihood function, in order to ensure that the desired constraints are satisfied. Rather than maximizing L(ψ | y), you can introduce a new parameter vector, θ, such that θ = g(ψ), where g(.) is a suitable continuous function. Then you maximize L(θ | y) = L(g(ψ) | y) with respect to ψ, and get the (constrained) estimate of θ as θ* = g(ψ*)
Very importantly, notice that if we are using MLE to estimate φ, this corresponding estimate of θ will also be the MLE - and not just some arbitrary estimator. This follows from the "invariance property" of MLE. (See this recent post.)
What constitutes a "suitable" function, g(.)? Let's look at some specific examples, some of which were suggested by Box (1966).
First, let's consider the case where there's just a single parameter to be estimated, so we can drop the subscripts on the parameter names.
First, let's consider the case where there's just a single parameter to be estimated, so we can drop the subscripts on the parameter names.
Suppose that we want the estimate of θ to be non-negative. In this case, all we need to do is to re-parameterize the model by setting θ = φ2. Then, whatever sign the estimate of φ takes, the estimate of θ will be non-negative.
We could also define θ = exp(φ). This will also ensure that the estimate of θ is strictly positive, regardless of the sign of the MLE for φ.
(You'll recall that this is what we do when we set up the Poisson regression model and make the conditional mean a positive function of the covariates. It's also how we ensure a positive variance when we have a regression model with "multiplicative" heteroskedasticity.)
(You'll recall that this is what we do when we set up the Poisson regression model and make the conditional mean a positive function of the covariates. It's also how we ensure a positive variance when we have a regression model with "multiplicative" heteroskedasticity.)
Obviously, if you want the estimate of θ to be negative, you can use the transformation θ = -exp(φ); etc.
You might think of using the transformation θ = |φ|. In fact, Box suggests this as one possibility. However, I prefer to avoid this particular transformation, for the following reason. The absolute value function is not fully differentiable - in particular, it's not differentiable at the origin, because at that point the left and right derivatives aren't equal. They take the values -1 and +1 respectively. It's not a good idea to use conventional "gradient methods" to try and maximize a non-differentiable function! (There are other options, but your favourite econometrics package may not include them.)
Range (Interval) Constraints
Range (Interval) Constraints
Now let's go back to our initial example of an interval constraint, say: 0 ≤ θ ≤ 1.
There are several ways of re-parameterizing the model to achieve this, including:
More generally, consider the restriction a ≤ θ ≤ b. In this case, the last transformation given above generalizes to
θ = a + (b - a) exp(φ) / [1 + exp(φ)] ,
and the other transformations generalize in a similar way.
Several Parameters
Now let's go back to the more general case where there are several parameters in the model. Here are some further examples of transformations of the parameter space that will enable you to "trick" an unconstrained optimization algorithm into giving you constrained results (e.g., see Box, 1966, pp. 72-73):
1. 0 ≤ θ1 ≤ θ2 ≤ θ3
In this case you can assign:
θ1 = ψ12
θ2 = ψ12 + ψ22
θ3 = ψ12 + ψ22 + ψ32,
and then undertake unconstrained optimization with respect to the elements of the ψ vector. Obviously, the quadratic functions could be replaced with exponential functions to achieve the same results.
2. 0 ≤ (θ1 + θ2) ≤ 1
One way to proceed in this case is to re-parameterize in the following way:
θ1 = ψ1
θ2 = {exp(ψ2) / [1 + exp(ψ2)]} - ψ1.
In this case the exponential functions could be replaced with squared values of the corresponding parameters.
You might give some thought to how you'd impose the constraints, a ≤ θ1 ≤ (θ2 + θ3) ≤ b.
One practical "problem" is that the estimates that are obtained in this way are often right on the boundary of the constraint that's being imposed. That is, weak inequality constraints will be satisfied by exact equality constraints.
There are several ways of re-parameterizing the model to achieve this, including:
- θ = sin2(φ)
- θ = φ2 / [1 + φ2]
- θ = exp(φ) / [1 + exp(φ)]
More generally, consider the restriction a ≤ θ ≤ b. In this case, the last transformation given above generalizes to
θ = a + (b - a) exp(φ) / [1 + exp(φ)] ,
and the other transformations generalize in a similar way.
Several Parameters
Now let's go back to the more general case where there are several parameters in the model. Here are some further examples of transformations of the parameter space that will enable you to "trick" an unconstrained optimization algorithm into giving you constrained results (e.g., see Box, 1966, pp. 72-73):
1. 0 ≤ θ1 ≤ θ2 ≤ θ3
In this case you can assign:
θ1 = ψ12
θ2 = ψ12 + ψ22
θ3 = ψ12 + ψ22 + ψ32,
and then undertake unconstrained optimization with respect to the elements of the ψ vector. Obviously, the quadratic functions could be replaced with exponential functions to achieve the same results.
2. 0 ≤ (θ1 + θ2) ≤ 1
One way to proceed in this case is to re-parameterize in the following way:
θ1 = ψ1
θ2 = {exp(ψ2) / [1 + exp(ψ2)]} - ψ1.
In this case the exponential functions could be replaced with squared values of the corresponding parameters.
You might give some thought to how you'd impose the constraints, a ≤ θ1 ≤ (θ2 + θ3) ≤ b.
One practical "problem" is that the estimates that are obtained in this way are often right on the boundary of the constraint that's being imposed. That is, weak inequality constraints will be satisfied by exact equality constraints.
To illustrate some of the ideas raised in this post, let's take a look at a few empirical examples. The (artificial) data-set and the EViews workfile that I've used can be found on this blog's data and code pages.
Let's consider the following regression model:
yi = β1 + β2 X1i + β3 X2i + β4 X3i + εi ; i = 1, 2, 3, ...., n.
Here are my OLS estimation results -
 |
| Output 1 |
Now, let's "impose" the (redundant) constraint, β2 ≥ 0. (You can see that the estimate, 2.6545, already satisfies this constraint.)
Let's use the "squaring" transformation to achieve this:

yielding the results:
 |
| Output 2 |
You can see that the results in Output 1 and Output 2 are identical, except for the second estimated "coefficient". In Output 1, the estimated coefficient of X1 is 2.654487. In Output 2 the parameter C(2) is squared to get the coefficient of X1. The square of -1.629260 is 2.654487. Go figure!
The positivity "restriction" that we imposed as redundant, so (quite correctly) none of the results were actually affected.
Example 2
Next, let's estimate the same model, but we'll impose the constraint, 0 ≤ β1 ≤ 1.
This constraint isn't satisfied in Output 1, as you can see. Here's one way of imposing the desired restriction - via the "logit" transformation:

Here are the results that we get:
 |
| Output 3 |
This time, not surprisingly, the estimation results are a little different from those in Output 1. The point estimate β1 in that output was 1.088837. Our constrained estimate of β1 is obtained as exp(C(1)) / (1 + exp(C(1))), whose value is 0.9999999992150385. Let's call this 1.0, shall we?
The desired constraint is satisfied, but as an equality.
The standard error associated with the OLS estimator of β1 in Output 1 was 1.566. How can we get a standard error for our constrained estimator? The estimate of β1 is obtained via the non-linear "logit" transformation. One common way to get a variance, standard deviation, or standard error for a non-linear function is the "Delta Method". (I'll go into this in more detail in a subsequent post.)
EViews (and most other similar packages) use the Delta Method for this purpose. To save you a lot of work, there's a simple way to "trick" EViews into giving us the standard error that we want in this case. I discussed it in this earlier post.
What we'll do is take the estimated model in Output 3, and then perform a Wald test of the restriction, exp(C(1)) / (1 + exp(C(1))) = 0. Among other things, this will give us the values of both the (constrained) point estimate and the associated standard error.
Let's see what we get:


We can see the estimated coefficient of 1.0, with a standard error of 1.565753. The latter value certainly seems sensible, given how similar it is to the corresponding standard error in Output 1. Strictly, the standard error we've obtained by the Delta Method is valid only asymptotically - that is, if the sample size is very large. We have n = 100, so we should have reasonable accuracy.
Incidentally, in this example if we use the transformation (C(1)^2) / (1 + C(1)^2), instead of the "logit" transformation, we obtain absolutely identical results.
Example 3
Now let's re-estimate the model while imposing the following constraints on the coefficients:
0 ≤ β1 ≤ 0 ; and 0 ≤ β2 ≤ β3. (Note that the first constraint isn't satisfied in Output 1, and neither is the latter part of the second constraint.)
Here's one way of achieving this:
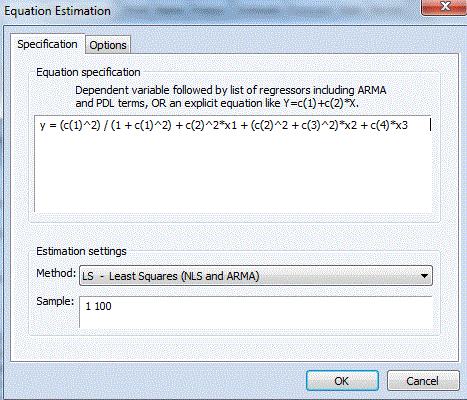
 |
| Output 4 |
To get the constrained estimates of the coefficients, and the associated standard errors, we can again use Wald tests:


In this case, the constraint 0 ≤ β1 ≤ 1 is satisfied weakly, with the value 0.727. On the other hand, the constraint, β2 ≤ β3 is satisfied with an equality.
Box (1966, 73-74) provides some additional examples. He also provides information about the effectiveness of different optimization algorithms.
The basic ideas that we've explored here are also mentioned in the EViews manual (or "Help" within the package itself). See "Limitations" under the description of the LOGL object.
A few final comments are in order:
- The examples we've looked at involved a linear regression model. The same methods can be used in the context of non-linear models.
- If the maximum of a likelihood function occurs on the boundary of the parameter space, this has (adverse) implications for the properties of the MLE and any associated tests. In some cases, this may be relevant in the context of what has been discussed here. This is a matter for a future post.
- Of course, we can also using Bayesian methods to ensure that estimated parameters satisfy desired inequality constraints. For example, see here for a consumption function example.
Reference
Box, M. J., 1966. A comparison of several current optimization methods, and the use of transformations in constrained problems. Computing Journal, 9, 67-77.
Nice discussion. I have a follow-up question, if you will. You say:
ReplyDelete"Most econometrics/statistics packages that allow you to set up an arbitrary likelihood function, and then maximize it, don't allow you to constrain the signs or magnitudes of the resulting point estimates."
Which I agree with. My question: why is this the case? Why don't most software packages build these features? Is it a philosophical rationale, wherein the software developers at Eviews, Stata, etc. allow for the tricks but don't want to encourage the use of inequality constraints by people who don't know exactly what they are doing?
Eric - no idea why they don't. The SHAZAM package used to have (maybe still has) the BAYES command that allows you to apply John Geweke's procedure for imposing inequality constraints. See Geweke, Journal of Applied Econometrics, 1986.
DeleteHi Dave,
ReplyDeleteI have a question related to the topic , the restrictions on the output of an equation. In some cases the dependent variable can only take certain values (a probability, prices, etc.) therefore some models can be easily adjusted to the data (probit, logit, ANN) or some data transformations can be made.
Nevertheless what if one wishes that the output of system of equations satisfy some restriction?
I tell you my specify problem, which can shed light on what I say, I have (for a research project) to forecast some shares of sectorial GDP. For this I adjust an Artificial Neural Network for each share, without weights for the activation function, each forecasted share It´s in the range [0,1] but the sum of these is not always equal to one.
Best regards,
Please see: http://davegiles.blogspot.ca/2015/06/readers-forum-page.html
ReplyDeleteThis is precisely the article that addresses my issue as I'd like to estimate a Poisson regression with positivity (or negativity) constraints on the parameters !! Thank you David !! Btw, I used to teach econometrics at the Australian National University (back then within the Department of Statistics). Adrian and Trevor had great things to say about you :-)
ReplyDeleteVery helpful. Thank you.
ReplyDeleteHi Prof Giles,
ReplyDeleteI would like to estimate a model by GMM with positivity constraints on the parameters.
Can I follow the approach you present for Maximum Likelihood?
Many thanks.
Kind regards,
PK
Yes, you certainly can. In fact you can do this with any estimator than involves optimizing some function.
DeleteMany thanks indeed Prof Giles.
DeleteThank you for your in-depth explanation. Do you have suggestions for how to impose non-positive constraints on coefficients in Stata (using either the nl or cnreg commands)?
ReplyDeleteHi - Check out https://www.stata.com/support/faqs/statistics/linear-regression-with-interval-constraints/
Deleteand https://www.stata.com/statalist/archive/2008-06/msg00217.html