In a recent post I posed the question: "How many decimal places (or maybe significant digits) are appropriate when reporting OLS regression results?"

I suggested that the answer depends on the number of decimal places and significant digits in the data that are being used, and I provided the following set of data:
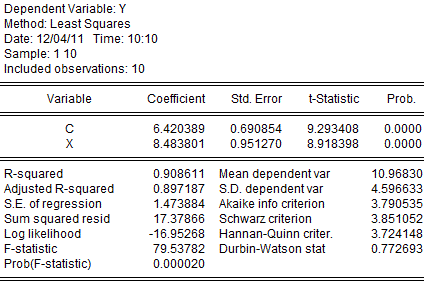
The corresponding results from gretl were:

(The previous post gives links to the data and the EViews and gretl files.)
Anyway, here are the specific questions that I asked.
Given the precision of the original data, what level of numerical precision (number of decimal places) do you think is really appropriate here when reporting:
- The estimated regression coefficients?
- The standard errors?
- The coefficient of determination (R2)?
To answer these questions, we need to recall the rules relating to numbers of decimal places, numbers of significant digits, and the way they're affected by the arithmetic operations of addition/subtraction and multiplication/division. Here are those rules (e.g., see about.com):
- Addition and subtraction:
"When measured quantities are used in addition or subtraction, the uncertainty is determined by the absolute uncertainty in the least precise measurement (not by the number of significant figures). Sometimes this is considered to be the number of digits after the decimal point."
- Multiplication and division:
(There's some good material on all of this on a web page authored by Christopher Mulliss.)"Whenexperimentalquantities are multiplied or divided, the number of significant figures in the result is the same as that in the quantity with the smallest number of significant figures."
Now, consider the first question above. We can write the OLS estimator of the slope coefficient as
b = Σ[(xi - xbar)(yi - ybar)] / Σ[(xi - xbar)2] = Σ[(xi - xbar)yi] / Σ[(xi - xbar)2] .
Here, the summations run from 1 to n ( = 10); xbar ( = 0.536069999....) is the sample mean of x; and ybar ( = 10.96830) is the sample mean of y.
So, the calculations needed for computing the OLS coefficient estimates simply involve lots of additions, subtractions, multiplications and divisions. (This is also true if there are more regressors in the model.)
In the following discussion it's very important to note that in practice we would "carry" as many decimal places as our computer allowed when making the calculations. Only at the very end of the exercise of computing the coefficient estimates would we do any "rounding off" of the answers to deal with relevant "accuracy".
When we look at the (second version of the) formula for b, the calculations for the numerator take the form:
The smaller number of digits after the decimal point associated with each subtraction is shown in brackets, in red. For all but the last two observations in this example the values in red also happen to be the number of significant digits. For the two exceptions, the number of significant digits are shown in braces, in green. Shown in parentheses, in blue, is the number of significant digits for each yi value.
When we take each product in the expression for this numerator, the appropriate numbers of resulting significant digits, term by term, are: 3, 2, 3, 2, 2, 2, 3, 2, 3, 3. The minimum of these is 2, which is the (implicit) precision of the numerator. Remember, we'll still retain all of the digits we have as we move forward with the rest of the calculations - we'll come back to this value, 2, shortly.
Now look at the denominator in the expression for b. The calculations are of the form:
So, the calculations needed for computing the OLS coefficient estimates simply involve lots of additions, subtractions, multiplications and divisions. (This is also true if there are more regressors in the model.)
In the following discussion it's very important to note that in practice we would "carry" as many decimal places as our computer allowed when making the calculations. Only at the very end of the exercise of computing the coefficient estimates would we do any "rounding off" of the answers to deal with relevant "accuracy".
When we look at the (second version of the) formula for b, the calculations for the numerator take the form:
(0.033-0.56307)(5.02) + (0.21-0.56307)(6.1) + (0.1234-0.56307)(7.34) + ...
[3] (3) [2] (2) [4] (3)
.....+ (1.01-0.56307)(16.01) + (1.67-0.56307)(18.7)
[2] (4) [2] (3)
{3} {3}
.....+ (1.01-0.56307)(16.01) + (1.67-0.56307)(18.7)
[2] (4) [2] (3)
{3} {3}
When we take each product in the expression for this numerator, the appropriate numbers of resulting significant digits, term by term, are: 3, 2, 3, 2, 2, 2, 3, 2, 3, 3. The minimum of these is 2, which is the (implicit) precision of the numerator. Remember, we'll still retain all of the digits we have as we move forward with the rest of the calculations - we'll come back to this value, 2, shortly.
Now look at the denominator in the expression for b. The calculations are of the form:
(0.033-0.56307)(0.033-0.56307) + (0.21-0.56307) (0.21-0.56307)
[3] [3] [2] [2]
+ (0.1234-0.56307)(0.1234-0.56307) + ..... + (1.01-0.56307)(1.01-0.56307)
+ (1.67-0.56307) (1.67-0.56307).
[2] [2]
{3} {3}
The colour-coded numbers have the same interpretation as before. When we take each product in the expression for this denominator, the appropriate numbers of resulting significant digits, term by term, are: 3, 2, 4, 3, 4, 2, 3, 2, 3, 3. The minimum of these is 2, which is the (implicit) precision of the denominator.
Finally, applying the second of the "rules" noted above, the value of b should be reported to just two significant digits - namely, as b = 8.5.
The OLS estimator for the intercept coefficient is
a = ybar - b (xbar) .
Applying the same reasoning to this much simpler calculation, we see that the estimated value of a should be reported to one decimal place. That is, a = 6.4
I'm going to leave you to figure out the answers for the standard errors and the R2 value, but somehow I doubt if any of this is going to catch on!
I also said that I had a slight preference for the gretl output. The reasons were three-fold:
[3] [3] [2] [2]
+ (0.1234-0.56307)(0.1234-0.56307) + ..... + (1.01-0.56307)(1.01-0.56307)
[4] [4] [2] [2]
{3} {3}
[2] [2]
{3} {3}
The colour-coded numbers have the same interpretation as before. When we take each product in the expression for this denominator, the appropriate numbers of resulting significant digits, term by term, are: 3, 2, 4, 3, 4, 2, 3, 2, 3, 3. The minimum of these is 2, which is the (implicit) precision of the denominator.
Finally, applying the second of the "rules" noted above, the value of b should be reported to just two significant digits - namely, as b = 8.5.
The OLS estimator for the intercept coefficient is
a = ybar - b (xbar) .
Applying the same reasoning to this much simpler calculation, we see that the estimated value of a should be reported to one decimal place. That is, a = 6.4
I'm going to leave you to figure out the answers for the standard errors and the R2 value, but somehow I doubt if any of this is going to catch on!
I also said that I had a slight preference for the gretl output. The reasons were three-fold:
- The reported values for a and b are (one digit) less "spuriously accurate".
- The p-values are reported in scientific notation, which is a little more "revealing".
- We are using cross-section data. This is declared explicitly when the gretl data file is created, and implicitly when the EViews workfile is declared not to be dealing with time-series or panel data. However, the EViews output still reports the Durbin-Watson statistic. This is appropriate only with time-series data, as the value of the statistic depends on the order of the data. In the case of cross-section data there is (generally) no natural order. We can re-order the (x and y) data without affecting the regression results, and each re-ordering will result in a different, but equally meaningless, Durbin-Watson statistic. The gretl results - wisely, in my view - do not report a (spurious) Durbin-Watson statistic in this case of cross-section data.
© 2011, David E. Giles
and what about the law of large numbers?
ReplyDeletewhen the reporting error in y is orthogonal to x i don't expect it to affect my estimates
as to x, i would expect classical reporting error to lead to attenuation bias
a little monte carlo using rounding confirms this:
clear all
cap program drop mysim
program mysim, rclass
args obs
drop _all
set obs `obs'
tempvar x y
tempname vx vxs
g `x' = rnormal()
sum `x'
scalar `vx' = r(Var)
// no measurement error because of rounding
g `y' = 1 + `x' + rnormal()
reg `y' `x'
return scalar c0 = _b[_cons]
return scalar b0 = _b[`x']
replace `y' = round(`y', 1)
// only y rounded
reg `y' `x'
return scalar c1 = _b[_cons]
return scalar b1 = _b[`x']
replace `x' = round(`x', 1)
sum `x'
scalar `vxs' = r(Var)
// both y and x are now rounded
reg `y' `x'
return scalar c2 = _b[_cons]
return scalar b2 = _b[`x']
// correct for measurement error bias because of rounding
return scalar b3 = _b[`x'] * `vxs' / `vx'
end
simulate c0 = r(c0) b0=r(b0) c1 = r(c1) b1=r(b1) c2 = r(c2) b2=r(b2) b3 = r(b3) , reps(4000) : mysim 1000
. tabstat *, c(s)
variable | mean
-------------+----------
c0 | .9996326
b0 | 1.000041
c1 | .9995353
b1 | 1.00018
c2 | .9996875
b2 | .9235341
b3 | 1.000294
------------------------
Mr. Ed: Fair enough point. The question is, though, without knowing you have "classical reporting error", as you put it, how many d.p. are you entitled to report?
ReplyDelete