When we think of the power curve associated with some statistical test, we usually envisage a curve that looks something like (half or all of) an inverted Normal density. That is, the curve rises smoothly and monotonically from a height equal to the significance level of the test (say 1% or 5%), until eventually it reaches its maximum height of 100%.
The latter value reflects the fact that power is a probability.
But is this picture that invariably comes to mind - and that we see reproduced in all elementary econometrics and statistics texts - really the full story?
Actually - no!
Let's look at a couple of "typical" power curves - one for the case where the alternative hypothesis is one-sided; and one for the case where a two-sided alternative hypothesis is used. In each case, I'll consider a "simple" null hypothesis, and a "composite" alternative hypothesis.
Recalling that the power of a test is the probability of rejecting H0, at the point where H0 is true the power equals the pre-assigned significance level of the test. At all other points in the parameter space the power the probability of rejecting H0, given that this hypothesis is false (in some way or another).
In the following chart, we see the power curve for a particular test for testing H0: θ = θ0, against HA: θ > θ0. Here, θ is a scalar parameter, and the significance level has been chosen to be 5%.
 In the next chart, we see the power curve for a test of the hypothesis, H0: θ = θ0, against HA: θ ≠ θ0. This time, the significance level has been chosen to be 10%.
In the next chart, we see the power curve for a test of the hypothesis, H0: θ = θ0, against HA: θ ≠ θ0. This time, the significance level has been chosen to be 10%.
 In each case, the power curve exhibits what we'd like to see - namely, a monotonic increase in the rate of rejection of H0 (i.e., an increase in power) as this null hypothesis becomes more and more false.
In each case, the power curve exhibits what we'd like to see - namely, a monotonic increase in the rate of rejection of H0 (i.e., an increase in power) as this null hypothesis becomes more and more false.
Regrettably, not all tests exhibit this desirable property - including some tests that we use in econometrics. The textbook power curves don't always emerge, and this seems to be something that a lot of practitioners are unaware of!
Before looking at some specific examples, note that in some cases the power curve isn't symmetric about the point θ0, as it is in the last graph.
More importantly, some hypothesis tests are what we call "biased". What this means is that for at least some value(s) of the parameter(s), the power curve falls to a level less than the assigned significance level of the test. In the last graph, if the blue line dipped to a height of less than 10%, anywhere (even if it subsequently rose and eventually got to 100%), then the test would be "biased".
Why is this an undesirable characteristic for a test? Well, recall the definitions of the significance level and the power of a test. The significance level is the probability of a Type I error - that is, Pr.[Reject H0 | H0 True]. The power, on the other hand, is one minus the probability of a Type II error - that is, Power = 1 - Pr.[Not Reject H0 | H0 False] = Pr. [Reject H0 | H0 False].
So, if power < significance level, then Pr. [Reject H0 | H0 False] < Pr.[Reject H0 | H0 True]. That is, at least some value(s) of the parameter(s), the probability of taking the correct action is less than the probability of taking the wrong action! We wouldn't want to be in that situation, would we?
Some of the tests that we use in econometrics can be biased in some circumstances. In fact, in some cases the situation is even worse - the power can fall to zero as the null hypothesis becomes more and more false!
Surely not? Unfortunately - yes!
Here are a couple of examples:
The RESET test
In a recent post I noted that Ramsey's (1969) Regression Specification Error Test (RESET) suffers from poor power properties in some circumstances. Although the test statistic is exactly F-distributed if the null hypothesis is true, under the alternative hypothesis its distribution (and hence its power properties) depend on the nature of the model mis-specification, and the choice of additional regressors that are used to augment the basic model for the purposes of testing for an invalid functional form or omitted regressors.
Here is just one example, taken from Ramsey and Gilbert (1972, p.184):
 Note that when the sample size (T) is 20 or 30, the power of the RESET test based on the OLS residuals is less than the significance level (α). The test is biased for the chosen values of the parameters.
Note that when the sample size (T) is 20 or 30, the power of the RESET test based on the OLS residuals is less than the significance level (α). The test is biased for the chosen values of the parameters.
Similar examples, such as the one depicted below, are reported by DeBenedictis and Giles (1998) in their comparison of the RESET test with their so-called FRESET test. (For more details, see this recent post.)
 Here, the two versions of the FRESET test exhibit increasing power as the model becomes increasingly mis-specified in a particular way, while the power function of the corresponding RESET test exhibits very unorthodox characteristics. We see that the latter test is biased over part of the parameter space. An explanation for the non-monotonic forms of the power curve is given by DeBenedictis and Giles (1998, pp. 401, 405).
Here, the two versions of the FRESET test exhibit increasing power as the model becomes increasingly mis-specified in a particular way, while the power function of the corresponding RESET test exhibits very unorthodox characteristics. We see that the latter test is biased over part of the parameter space. An explanation for the non-monotonic forms of the power curve is given by DeBenedictis and Giles (1998, pp. 401, 405).
The Durbin-Watson test
 Krämer and Sonnberger (1986, pp.19-22) show that this can also occur as ρ approaches -1 in value.
Krämer and Sonnberger (1986, pp.19-22) show that this can also occur as ρ approaches -1 in value.
In other words, just when you really want the test to reject the null hypothesis, the probability of it doing so is zero!
[Of course, the usual bounds for the critical values for the DW test don't apply if you fit the model through the origin, but that's another matter.]
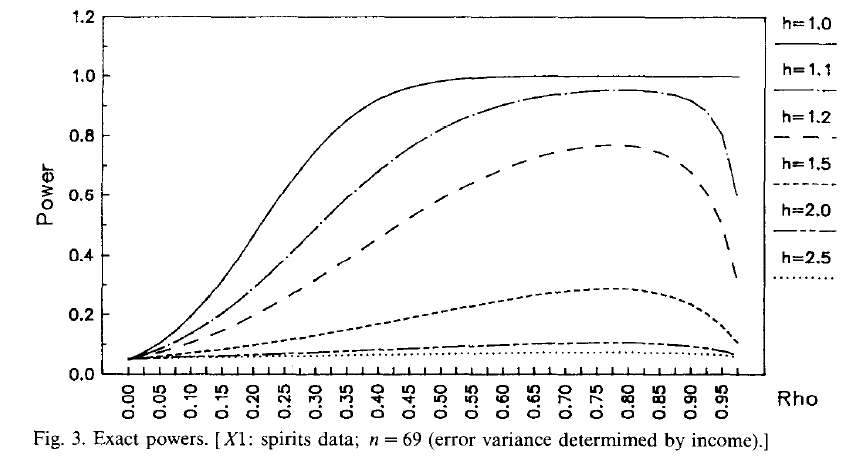
Less extreme examples of declining power for the DW test can occur if the errors are heteroskedastic, even when the model includes an intercept. For example, the following graph is taken from Giles and Small, 1991, p.40), where increasing values of "h" reflect more and more severe heteroskedasticity:
 Once again, the DW test performs badly when it is most needed!
Once again, the DW test performs badly when it is most needed!
So, although the textbook depictions of power curves are helpful in describing some of the characteristics of certain tests, they don't cover all of the situations that we may encounter. This isn't surprising, but it's worth keeping in mind as we go about our day-to-day econometric practice.
Don't presume that all is well!
References
DeBenedictis, L. F. and D. E. A. Giles, 1998. Diagnostic testing in econometrics: Variable addition, RESET, and Fourier approximations. In A. Ullah and D. E. A. Giles (eds.), Handbook of Applied Economic Statistics, Marcel Dekker, New York, 383-417. WP version; figures.)
Giles, D. E. A. and J. P Small, 1991. The power of the Durbin-Watson test when the errors are heteroscedastic. Economics Letters, 36, 37-41.
Krämer, W., 1985. The power of the Durbin-Watson test for regression without an intercept. Journal of Econometrics, 28, 363-370.
Krämer, W. and H. Sonnberger, 1986. The Linear Regression Model Under Test, Physica-Verlag, Heidelberg.
Ramsey, J. B., 1969. Tests for specification errors in classical linear least squares regression analysis. Journal of the Royal Statistical Society, Series B, 31, 350–371.
Ramsey, J. and R. Gilbert, 1972. A Monte Carlo study of some small sample properties of tets for specification error. Journal of the American Statistical Association, 67, 180-186.
Regrettably, not all tests exhibit this desirable property - including some tests that we use in econometrics. The textbook power curves don't always emerge, and this seems to be something that a lot of practitioners are unaware of!
Before looking at some specific examples, note that in some cases the power curve isn't symmetric about the point θ0, as it is in the last graph.
More importantly, some hypothesis tests are what we call "biased". What this means is that for at least some value(s) of the parameter(s), the power curve falls to a level less than the assigned significance level of the test. In the last graph, if the blue line dipped to a height of less than 10%, anywhere (even if it subsequently rose and eventually got to 100%), then the test would be "biased".
Why is this an undesirable characteristic for a test? Well, recall the definitions of the significance level and the power of a test. The significance level is the probability of a Type I error - that is, Pr.[Reject H0 | H0 True]. The power, on the other hand, is one minus the probability of a Type II error - that is, Power = 1 - Pr.[Not Reject H0 | H0 False] = Pr. [Reject H0 | H0 False].
So, if power < significance level, then Pr. [Reject H0 | H0 False] < Pr.[Reject H0 | H0 True]. That is, at least some value(s) of the parameter(s), the probability of taking the correct action is less than the probability of taking the wrong action! We wouldn't want to be in that situation, would we?
Some of the tests that we use in econometrics can be biased in some circumstances. In fact, in some cases the situation is even worse - the power can fall to zero as the null hypothesis becomes more and more false!
Surely not? Unfortunately - yes!
Here are a couple of examples:
The RESET test
In a recent post I noted that Ramsey's (1969) Regression Specification Error Test (RESET) suffers from poor power properties in some circumstances. Although the test statistic is exactly F-distributed if the null hypothesis is true, under the alternative hypothesis its distribution (and hence its power properties) depend on the nature of the model mis-specification, and the choice of additional regressors that are used to augment the basic model for the purposes of testing for an invalid functional form or omitted regressors.
Here is just one example, taken from Ramsey and Gilbert (1972, p.184):

Similar examples, such as the one depicted below, are reported by DeBenedictis and Giles (1998) in their comparison of the RESET test with their so-called FRESET test. (For more details, see this recent post.)

The Durbin-Watson test
Krämer (1985) shows that in the case of an OLS regression fitted without an intercept, for certain choices of X data the Durbin-Watson test is not only biased, but its power falls to zero when the first-order autocorrelation coefficient (ρ) approaches 1. The following graph is from Krämer (1985, p.367):

In other words, just when you really want the test to reject the null hypothesis, the probability of it doing so is zero!
[Of course, the usual bounds for the critical values for the DW test don't apply if you fit the model through the origin, but that's another matter.]
Less extreme examples of declining power for the DW test can occur if the errors are heteroskedastic, even when the model includes an intercept. For example, the following graph is taken from Giles and Small, 1991, p.40), where increasing values of "h" reflect more and more severe heteroskedasticity:
So, although the textbook depictions of power curves are helpful in describing some of the characteristics of certain tests, they don't cover all of the situations that we may encounter. This isn't surprising, but it's worth keeping in mind as we go about our day-to-day econometric practice.
Don't presume that all is well!
References
DeBenedictis, L. F. and D. E. A. Giles, 1998. Diagnostic testing in econometrics: Variable addition, RESET, and Fourier approximations. In A. Ullah and D. E. A. Giles (eds.), Handbook of Applied Economic Statistics, Marcel Dekker, New York, 383-417. WP version; figures.)
Giles, D. E. A. and J. P Small, 1991. The power of the Durbin-Watson test when the errors are heteroscedastic. Economics Letters, 36, 37-41.
Krämer, W., 1985. The power of the Durbin-Watson test for regression without an intercept. Journal of Econometrics, 28, 363-370.
Krämer, W. and H. Sonnberger, 1986. The Linear Regression Model Under Test, Physica-Verlag, Heidelberg.
Ramsey, J. B., 1969. Tests for specification errors in classical linear least squares regression analysis. Journal of the Royal Statistical Society, Series B, 31, 350–371.
Ramsey, J. and R. Gilbert, 1972. A Monte Carlo study of some small sample properties of tets for specification error. Journal of the American Statistical Association, 67, 180-186.
© 2012, David E. Giles
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.