I'm currently teaching first-level course in statistical inference for (mostly) economics students. They've taken a one-semester course in descriptive (economic) statistics, and now we're dealing with sampling distributions, estimation, hypothesis testing, and simple regression analysis.
When dealing with the sampling distribution of the sample mean, based on simple random sampling, we derived the result that this distribution has a mean of μ and a variance of σ2/n. Here, μ and σ2 are the population mean and variance, and n is the sample size. I then told the class that if the population happens to be Normal, then the sampling distribution of the sample average will also be Normal - because linear combinations of Normal random variables are also Normally distributed.
In fact, this result holds even if the random variables are jointly Normal, and not independent.
We then got to a discussion of the sampling distribution of the sample variance, s2. We proved that E[s2] = σ2, regardless of the population distribution. However, to proceed further I considered only the case of a Normal population, and introduced the students to the Chi-Square distribution. We established that [(n-1)s2/σ2] follows a Chi-Square distribution with (n-1) degrees of freedom.
[The sample average and s2 are also statistically independent if the population is Normal. For some reason, students at this level generally aren't told that this result requires Normality.]
At this point, as a by-product of the material we'd covered, the students knew that:
[The sample average and s2 are also statistically independent if the population is Normal. For some reason, students at this level generally aren't told that this result requires Normality.]
At this point, as a by-product of the material we'd covered, the students knew that:
- Linear combinations of Normal random variables are also Normally distributed.
- Sums of (independent) Chi-Square random variables are also Chi-Square distributed.
It would be understandable if a student then presumed that any linear combination of independent Chi-Square variates is Chi-Square distributed. However, this is not the case. Even the difference of two such variables doesn't follow a Chi-Square distribution.
It would also be understandable for a student to presume that, perhaps, sums of independent random variables from the same distribution, also follow that distribution. Not so!
Students at this level have generally met very few statistical distributions. Usually, the first one that they encounter is the Binomial distribution. Sums of independent Binomial random variables (with the same "success" probability, p) are in fact also Binomially distributed. Specifically, if X1 ~ Bi[m , p] and X2 ~ Bi[n , p], then (X1 + X2) ~ Bi[(m+n) , p]. This is a trivial result, given the independence of X1 and X2, and the definition of a Binomial random variable in terms of Bernoulli trials.
But what about something as simple as adding together two independent random variables, U1 and U2, that each follow a Uniform distribution on [0 , 1]? Does this result in a new random variable that is Uniformly distributed? No, it doesn't!
First of all, it's easy to see that the "support" of the distribution of this sum (the range of values it can take) is [0 , 2], not [0 , 1].
To do this, I've generated a million independent values of U1 and U2, added them together, and then plotted the result. You can do this using EViews, with the commands:
SMPL 1 1000000
SERIES U1=@RUNIF(0,1)
SERIES U2=@RUNIF(0,1)
SERIES Z=U1+U2
SHOW Z
HIST Z
If you graph Z, using the options: Distribution; Histogram; Density; Bin-width user-specified as 0.02; you get:
 Using the following commands in R:
Using the following commands in R:
you get:
.gif) O.K., it seems that the density function is triangular in shape. [Cross-check: the area of the triangle is "1", as it should be for a density. That's a good start!]
O.K., it seems that the density function is triangular in shape. [Cross-check: the area of the triangle is "1", as it should be for a density. That's a good start!]
Now, if you want to establish this result mathematically, rather than by simulation, there are several ways to do it. One is by taking the so-called "convolution of the densities of U1 and U2. For full details, see p.292 of the material supplied by the "Chance" team at Dartmouth College.
An alternative way of getting the density function for Z is to take the mapping from the joint density of U1 and U2 to the joint density of Z and W = (U1 - U2). The Jacobian for this transformation is 1/2. Once you have the joint density of Z and W, you can then integrate out with respect to W, to get the triangular density for Z.
This triangular distribution that emerges when you add two independent U[0 ,1] variates together is actually just a special case of the so-called Irwin-Hall distribution. The latter arises when you take the sum of, say, k independent U[0 ,1] random variables.
Here's what the density for this sum looks like, for various choices of k:
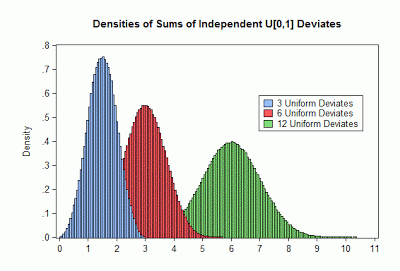 You can see that you don't have to have a very large value for k before the density looks rather like that of a Normal random variable, with a mean of (k/2). In fact, this gives a "quick-and dirty" way of generating a normally distributed random value. We can see this if we take k = 12, and subtract 6 from the sum:
You can see that you don't have to have a very large value for k before the density looks rather like that of a Normal random variable, with a mean of (k/2). In fact, this gives a "quick-and dirty" way of generating a normally distributed random value. We can see this if we take k = 12, and subtract 6 from the sum:

(We don't need to do any scaling to get the variance equal to one in value - remember that the variance of a U[0 , 1] variable is 1/12, and we're summing 12 independent such variables.)
Of course, there are much better ways than this to generate Normal variates, but I won't go into that here.
There's an interesting, more general, question that we could also ask. What happens if we take the sum of independent random variables which are Uniformly distributed, but over different ranges?
In this case, things get much more complicated. There have been some interesting contributions to this problem by Mitra (1971), Sadooghi-Alvandi (2009), and others.
References
Hall, P., 1927. The Distribution of Means for Samples of Size N Drawn from a Population in which the Variate Takes Values Between 0 and 1, All Such Values Being Equally Probable. Biometrika, 19, 240–245.
Irwin, J.O., 1927. On the Frequency Distribution of the Means of Samples from a Population Having any Law of Frequency with Finite Moments, with Special Reference to Pearson's Type II. Biometrika, 19, 225–239.
Mitra, S. K., 1971. On the Probability Distribution of the Sum of Uniformly Distributed Random Variables. SIAM Journal of Applied Mathematics, 20, 195-198.
Sadooghi-Alvandi, S., A. Nematollahi, & R. Habibi, 2009. On the Distribution of the Sum of Independent Uniform Random Variables. Statistical Papers, 50, 171-175.
To do this, I've generated a million independent values of U1 and U2, added them together, and then plotted the result. You can do this using EViews, with the commands:
SMPL 1 1000000
SERIES U1=@RUNIF(0,1)
SERIES U2=@RUNIF(0,1)
SERIES Z=U1+U2
SHOW Z
HIST Z
If you graph Z, using the options: Distribution; Histogram; Density; Bin-width user-specified as 0.02; you get:

u1=runif(1000000)
u2=runif(1000000)
z=u1+u2
hist(z, freq=FALSE, breaks=100, col="lightblue", main="Density of Z")
you get:
.gif)
Now, if you want to establish this result mathematically, rather than by simulation, there are several ways to do it. One is by taking the so-called "convolution of the densities of U1 and U2. For full details, see p.292 of the material supplied by the "Chance" team at Dartmouth College.
An alternative way of getting the density function for Z is to take the mapping from the joint density of U1 and U2 to the joint density of Z and W = (U1 - U2). The Jacobian for this transformation is 1/2. Once you have the joint density of Z and W, you can then integrate out with respect to W, to get the triangular density for Z.
This triangular distribution that emerges when you add two independent U[0 ,1] variates together is actually just a special case of the so-called Irwin-Hall distribution. The latter arises when you take the sum of, say, k independent U[0 ,1] random variables.
Here's what the density for this sum looks like, for various choices of k:


(We don't need to do any scaling to get the variance equal to one in value - remember that the variance of a U[0 , 1] variable is 1/12, and we're summing 12 independent such variables.)
Of course, there are much better ways than this to generate Normal variates, but I won't go into that here.
There's an interesting, more general, question that we could also ask. What happens if we take the sum of independent random variables which are Uniformly distributed, but over different ranges?
In this case, things get much more complicated. There have been some interesting contributions to this problem by Mitra (1971), Sadooghi-Alvandi (2009), and others.
References
Hall, P., 1927. The Distribution of Means for Samples of Size N Drawn from a Population in which the Variate Takes Values Between 0 and 1, All Such Values Being Equally Probable. Biometrika, 19, 240–245.
Irwin, J.O., 1927. On the Frequency Distribution of the Means of Samples from a Population Having any Law of Frequency with Finite Moments, with Special Reference to Pearson's Type II. Biometrika, 19, 225–239.
Mitra, S. K., 1971. On the Probability Distribution of the Sum of Uniformly Distributed Random Variables. SIAM Journal of Applied Mathematics, 20, 195-198.
Sadooghi-Alvandi, S., A. Nematollahi, & R. Habibi, 2009. On the Distribution of the Sum of Independent Uniform Random Variables. Statistical Papers, 50, 171-175.
© 2013, David E. Giles
I would like to know the textbook you're using and whether the student's are required to do a lot of exercises using R or any other software?
ReplyDeleteI'm using P. Newbold, W. L. Carlson & B. Thorne, "Statistics for Business and Economics", 7th ed., 2010, or 8th ed., 2013, Prentice Hall. It's an Economics Statistics course, so we're using EViews for the exercises, lab. classes, etc.
DeleteAs an Econ undergrad and grad student I met very few distributions myself. In fact, at one point I was riding in a car with two profs and one sneakily shot out the question "How is the ratio of two normally distributed variables distributed?" I just sort of said "Uuuuuuh" until the other one jumped on it with "Cauchy Distribution". I continued to sit there with a vacant expression on my face because I had no idea how this could be valuable information now or in the future.
ReplyDeleteFast forward to when I am explaining to undergraduates that the ratio of two chi-square distributed variables divided by their degrees of freedom is an F-distribution and I see the very same faces I made during that car ride. Meeting the distribution isn't the issue, it's seeing when you could use this information, which is difficult.
What exactly are you doing in R here? It seems like you are using a very interesting way of programming in R, but I can not get it to run. How does this work?
ReplyDeleteBlogger scrambled the R code! I think it will make more sense now. Thanks for alerting me.
DeleteAh, now I see what is actually happening. Thanks!
Delete