This post is the third in a series of posts that I'm writing about Monte Carlo (MC) simulation, especially as it applies to econometrics. If you've already seen the first two posts in the series (here and here) then you'll know that my intention is to provide a very elementary introduction to this topic. There are lots of details that I've been avoiding, deliberately.
In this post we're going to pick up from where the previous post about estimator properties based on the sampling distribution left off. Specifically, I'll be applying the ideas that were introduced in that post in the context of regression analysis. We'll take a look at the properties of the Least Squares estimator in three different situations. In doing so, I'll be able to illustrate, through simulation, some "text book" results that you'll know about already.
If you haven't read the immediately preceding post in this series already, I urge you to do so before continuing. The material and terminology that follow will assume that you have.
Now, to get things started, let's consider a basic linear regression model of the following form:
yi = β1 + β2x2i + β3x3i + εi ; i = i, 2, ...., n (1)
The observed values for the regressors, x2 and x3, will be non-random. They'll be what we call "fixed in repeated samples", and the real meaning of the latter expression will become totally transparent shortly. The values of x2 in our sample won't all be a constant multiple of the corresponding values of x3. (You'll recognize that I'm making sure that we don't have "perfect multicollinearlity.)
The coefficients of the model - β1, β2, and β3 - will be fixed parameters. In practice, we won't know their true values - indeed, one purpose of the model is to estimate these values.
To complete the specification of the model, we need to be really clear about the assumed properties of the random error term, ε. In a sense, the error term is the most interesting part of the model - without it, the model would be purely deterministic, and there would be no "statistical" problem for us to solve.
Here's what we're going to assume (and actually impose explicitly into the MC experiment):
The random values of ε are pair-wise uncorrelated, and come from a Normal distribution with a mean of zero, and a variance of σ2. This variance is also an unknown constant parameter that's positive and finite in value. Again, estimating this value is one thing that might interest us. Being uncorrelated, and also normally distributed, the values of the random error term are actually statistically independent.
The model in (1), together with the various assumptions about the regressors, about the parameters, and about the random nature of the error term, represent what we can refer to as the "Data-Generating Process" (DGP) for the dependent variable, y. As you'll know, the values taken by y will be realized values of a random process, because of the presence of the ε random variable on the right of (1). In reality, the values of ε won't be observed. They're coming from the underlying population.
In our MC experiment, what we're going to do is to generate lots and lots of samples of size "n" for the y variable; use these data and the data for x2 and x3 to estimate the parameters in (1) by Ordinary Least Squares (OLS), lots of times; and then use this information to mimic the sampling distributions of the parameter estimators.
Once we've seen how all of this works in the case of a "standard" linear regression model, we'll take a quick look at a couple of extensions by considering a model in which one of the regressors is a lagged value of dependent variable; and one which is non-linear in the parameters.
I've done all of this using the EViews econometrics package, and you can find my workfile and programs on the code page for this blog. You can open the programs with any text editor, if you're not an EViews user. If you use my workfile with EViews, note that it contains three pages - one for each of the examples that I go through in this post.
Looking back at the second post in this sequence, we can see that the steps that we have to go through in very general terms are as follows:
Now let's re-phrase these steps so that they are stated more explicitly in terms of our specific regression estimation problem. Here's what they become:
1. Assign values to the parameters, β1, β2, β3, and σ.
I've set the value of N to be 5,000 in what follows. The values of the three regression coefficients have been assigned to be 1.0, 1.0, and 3.0 respectively, and the variance of the error term is 1.0.
(Of course, the results are specific to this choice of values for the parameters, but for this particular experiment you'll know already that OLS is an unbiased estimator. This result holds regardless of the true values of the parameters,)
To conserve space I'll focus on the estimation of just one of the parameters, namely β2. The corresponding OLS estimator will be labelled b2.
In Figure 1 you can see the results that I obtained when I ran the MC simulation with n = 10:

Now let's increase the sample size, n, for our estimation problem. The results for n = 100 can be seen in Figure 2.
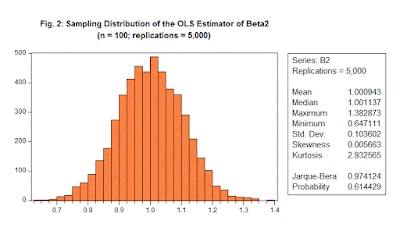
There are several things that are apparent from these two figures and the associated summary statistics.
First, regardless of the sample size, the mean value of the sampling distribution for b2 is extremely close to 1.0, and that's the true value for β2 that we assigned in the DGP. That is, E[b2] is essentially equal to β2. In fact, any discrepancy is simply due to sampling error - we've used only N = 5,000 replications, not an infinity of them.
Second, the standard deviation of the sampling distribution for b2 falls from 0.398 to 0.104 as the sample size increases. If we made n very large indeed, this standard deviation would approach zero. (Running this experiment with n = 10,000 yields a standard deviation for b2 that is 0.016.)
Third, regardless of the sample size, the Jarque-Bera test statistic supports the hypothesis that the 5,000 values that mimic the sampling distribution of b2 follow a normal distribution.
So, among the things that we've been able to demonstrate (not prove) by conducting this MC experiment are:
1. At least for the set of parameter values that we've considered, OLS seems to be an unbiased estimator of the regression coefficients under the conditions adopted in the MC experiment.
2. At least for the set of parameter values that we've considered, OLS seems to be a mean-square consistent (and hence weakly consistent) estimator of the regression coefficients under the conditions adopted in the MC experiment.
3. At least for the set of parameter values that we've considered, the OLS coefficient estimator seems have a sampling distribution that is Normal, even when the sample size, n, is very small.
If we were to repeat this experiment with different true values for the parameters in the DGP, we'd keep coming to the same conclusion. This might lead us to suspect (correctly in this case) that these properties of the OLS estimator apply for any values of the parameters.
That, in turn, might motivate us to try and establish this result with a formal mathematical proof. In fact, this "inter-play" between simulation experiments and formal mathematical derivations is an important way of establishing new theoretical results in econometrics.
Now let's move to the second part of this post, where we'll look at a simple MC experiment that will demonstrate the fact that when we have a (time-series) regression model that has a lagged value of the dependent variable, y, included as a regressor, the OLS estimator for the coefficient vector is biased if the sample size is finite.
In this case, the simple "dynamic" model that will form our DGP is:
yt = α + β yt-1 + ut ; t = 1, 2, 3, ......, n. (2)
The random values of u are pair-wise uncorrelated, and come from a Normal distribution with a mean of zero, and a (positive, finite) variance of σ2.
From the discussion above, you can easily see what steps are followed in each replication of the MC experiment. One important thing to notice in this case, however, is that the (non-constant) regressor in the model is no longer "fixed in repeated samples". Each time that we generate a new sample of yt values, we'll also have a new sample of yt-1 values. So, in this case we have a regressor that is non-random. (However, it's not correlated with the error term, because we're explicitly forcing the latter to take values that are independent over time (i.e., serially independent).)
Figures 3 to 7 illustrate some of the results from our experiment. The OLS estimators for both α and β are in fact biased, but to conserve space we demonstrate this just for β. The OLS estimator for this parameter is labelled "b". Our MC experiment is again based on N = 5,000 replications. The sample sizes that have been considered are n = 10, 30, 100, 500, and 3,000. The values that were assigned to α, β, and σ in the DGP were 1.0, 0.5, and 1.0 respectively.
 In Figures 3 to 6 we see that b is a downward-biased estimator of β when the sample size is small. In Figure 6, n = 500, and the bias in b is relatively small (although still around -5%). Even with a sample of this size we can see that the sampling distribution of b is skewed to the left and has excess kurtosis. This sampling distribution is non-Normal, even though the error term has been drawn from a Normal distribution!
In Figures 3 to 6 we see that b is a downward-biased estimator of β when the sample size is small. In Figure 6, n = 500, and the bias in b is relatively small (although still around -5%). Even with a sample of this size we can see that the sampling distribution of b is skewed to the left and has excess kurtosis. This sampling distribution is non-Normal, even though the error term has been drawn from a Normal distribution!
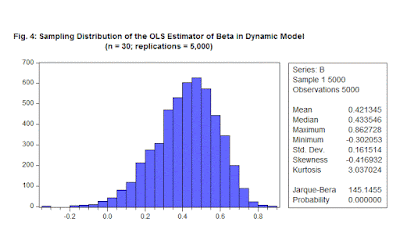


 In Figure 7, with n = 3,000, we see from the Jarque-Bera test statistic that the Normal asymptotic distribution for b has finally been well approximated. In addition, the (large-sample) bias is now negligible. This is as it should be, because the disturbances are independent (they don't exhibit any autocorrelation), so b is a weakly consistent estimator of β. (You'll notice that the standard deviation of the sampling distribution for b also fell steadily in value as n increased.)
In Figure 7, with n = 3,000, we see from the Jarque-Bera test statistic that the Normal asymptotic distribution for b has finally been well approximated. In addition, the (large-sample) bias is now negligible. This is as it should be, because the disturbances are independent (they don't exhibit any autocorrelation), so b is a weakly consistent estimator of β. (You'll notice that the standard deviation of the sampling distribution for b also fell steadily in value as n increased.)
Our third experiment investigates some of the properties of lease squares when it is applied to a model that is non-linear in the parameters. You may know already that, in general, the non-linear least squares (NLLS) estimator is biased, although weakly consistent under standard conditions. Let's see if we can illustrate this.
In this case we'll consider the following regression model:
yi = α + βxiγ+ ei ; i = 1, 2, 3, ..., n (3)
Once again, the values of x will be "fixed in repeated samples" (so the same values will be used, for a given value of n, in each replication of the MC experiment). The error term, e, takes values that are drawn independently from an N[0 , σ2] distribution. I have fixed the values of the parameters to α = 1.0, β = 1.0, γ = 3.0, and σ = 1.0 throughout the experiment.
The MC results for n = 10, 25, and 100 appear in Figures 8 to 10 below.


 As it happens, the NLLS estimator of beta has negligible bias in this particular case, even when n is very small. In general, the NLLS estimator will be biased, so this is an important illustration of the point that the results of a MC experiment are specific to the circumstances (DGP and data) that are being investigated. They may not hold in other situations!
As it happens, the NLLS estimator of beta has negligible bias in this particular case, even when n is very small. In general, the NLLS estimator will be biased, so this is an important illustration of the point that the results of a MC experiment are specific to the circumstances (DGP and data) that are being investigated. They may not hold in other situations!
Once again, the fact that the standard deviation of the sampling distribution of b declines as the sample size increases is a reflection of the weak consistency of the NLLS estimator. Finally, we can see that even though the error term in the model is Normally distributed, the sampling distribution of the NLLS estimator of beta is non-Normal for small samples. However, this distribution is asymptotically Normal. (Look at the skewness and kurtosis coefficients in Figures 8 to 10, and the associated Jarqe-Bera test statistics.)
Hopefully, the three regression examples that I've considered in this post will provide a good idea of how we can explore just a few of the (sampling) properties of some familiar estimators by using Monte Carlo simulation.
There's lots more that we can do, and I'll provide some further examples relating to both estimation and hypothesis testing in some upcoming posts on this general topic.
In this post we're going to pick up from where the previous post about estimator properties based on the sampling distribution left off. Specifically, I'll be applying the ideas that were introduced in that post in the context of regression analysis. We'll take a look at the properties of the Least Squares estimator in three different situations. In doing so, I'll be able to illustrate, through simulation, some "text book" results that you'll know about already.
If you haven't read the immediately preceding post in this series already, I urge you to do so before continuing. The material and terminology that follow will assume that you have.
Now, to get things started, let's consider a basic linear regression model of the following form:
yi = β1 + β2x2i + β3x3i + εi ; i = i, 2, ...., n (1)
The observed values for the regressors, x2 and x3, will be non-random. They'll be what we call "fixed in repeated samples", and the real meaning of the latter expression will become totally transparent shortly. The values of x2 in our sample won't all be a constant multiple of the corresponding values of x3. (You'll recognize that I'm making sure that we don't have "perfect multicollinearlity.)
The coefficients of the model - β1, β2, and β3 - will be fixed parameters. In practice, we won't know their true values - indeed, one purpose of the model is to estimate these values.
To complete the specification of the model, we need to be really clear about the assumed properties of the random error term, ε. In a sense, the error term is the most interesting part of the model - without it, the model would be purely deterministic, and there would be no "statistical" problem for us to solve.
Here's what we're going to assume (and actually impose explicitly into the MC experiment):
The random values of ε are pair-wise uncorrelated, and come from a Normal distribution with a mean of zero, and a variance of σ2. This variance is also an unknown constant parameter that's positive and finite in value. Again, estimating this value is one thing that might interest us. Being uncorrelated, and also normally distributed, the values of the random error term are actually statistically independent.
The model in (1), together with the various assumptions about the regressors, about the parameters, and about the random nature of the error term, represent what we can refer to as the "Data-Generating Process" (DGP) for the dependent variable, y. As you'll know, the values taken by y will be realized values of a random process, because of the presence of the ε random variable on the right of (1). In reality, the values of ε won't be observed. They're coming from the underlying population.
In our MC experiment, what we're going to do is to generate lots and lots of samples of size "n" for the y variable; use these data and the data for x2 and x3 to estimate the parameters in (1) by Ordinary Least Squares (OLS), lots of times; and then use this information to mimic the sampling distributions of the parameter estimators.
Once we've seen how all of this works in the case of a "standard" linear regression model, we'll take a quick look at a couple of extensions by considering a model in which one of the regressors is a lagged value of dependent variable; and one which is non-linear in the parameters.
I've done all of this using the EViews econometrics package, and you can find my workfile and programs on the code page for this blog. You can open the programs with any text editor, if you're not an EViews user. If you use my workfile with EViews, note that it contains three pages - one for each of the examples that I go through in this post.
Looking back at the second post in this sequence, we can see that the steps that we have to go through in very general terms are as follows:
1. Assign a "realistic", or interesting, value to the parameter vector, θ. (The results will be conditioned on this choice.)
2. Generate a random sample of fixed size (say, n) from p(y | θ).
3. Compute the value of an estimator of θ, say θ*, based on this particular y vector, and store this value.
4. Repeat steps 2 and 3 many, many times. Suppose the number of replications that you decide to use is N.
5. You will now have N different values of θ*, each based on a different (independent) sample of size n.
1. Assign values to the parameters, β1, β2, β3, and σ.
2. Generate n independent random εi values from a N[0 , σ2] distribution. Then use these values, the values for the parameters, and a set of n values for x1 and x2 to generate a random sample of yi values, using equation (1).
When we look at the empirical distributions of these N estimates what we're looking at is an approximation to the sampling distribution of the corresponding OLS estimator of one of the parameters.
3. Compute the OLS estimates of the regression parameters, based on this particular y vector, and store these estimates.
4. Repeat steps 2 and 3 many, many times. Suppose the number of replications that you decide to use is N. In each case the same parameter values and sample values for x2 and x3 will be used. However, because different εi values will be used each time, the sample of yi values will also differ at each replication.
5. We'll now have N different estimates of the parameters, each based on a different (independent) sample of size n.
(Of course, the results are specific to this choice of values for the parameters, but for this particular experiment you'll know already that OLS is an unbiased estimator. This result holds regardless of the true values of the parameters,)
To conserve space I'll focus on the estimation of just one of the parameters, namely β2. The corresponding OLS estimator will be labelled b2.
In Figure 1 you can see the results that I obtained when I ran the MC simulation with n = 10:

Now let's increase the sample size, n, for our estimation problem. The results for n = 100 can be seen in Figure 2.
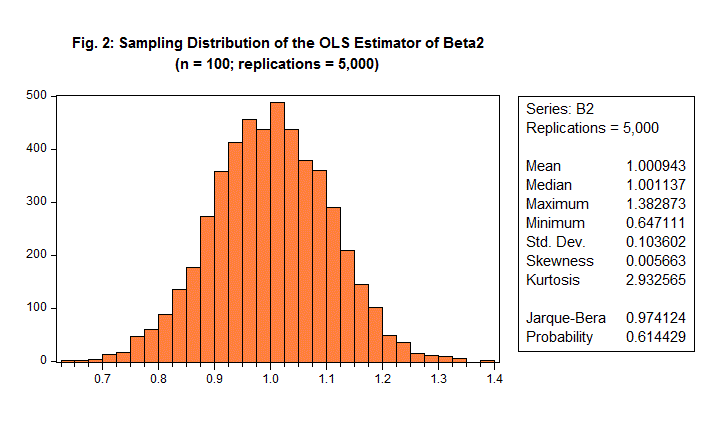
There are several things that are apparent from these two figures and the associated summary statistics.
First, regardless of the sample size, the mean value of the sampling distribution for b2 is extremely close to 1.0, and that's the true value for β2 that we assigned in the DGP. That is, E[b2] is essentially equal to β2. In fact, any discrepancy is simply due to sampling error - we've used only N = 5,000 replications, not an infinity of them.
Second, the standard deviation of the sampling distribution for b2 falls from 0.398 to 0.104 as the sample size increases. If we made n very large indeed, this standard deviation would approach zero. (Running this experiment with n = 10,000 yields a standard deviation for b2 that is 0.016.)
Third, regardless of the sample size, the Jarque-Bera test statistic supports the hypothesis that the 5,000 values that mimic the sampling distribution of b2 follow a normal distribution.
So, among the things that we've been able to demonstrate (not prove) by conducting this MC experiment are:
1. At least for the set of parameter values that we've considered, OLS seems to be an unbiased estimator of the regression coefficients under the conditions adopted in the MC experiment.
2. At least for the set of parameter values that we've considered, OLS seems to be a mean-square consistent (and hence weakly consistent) estimator of the regression coefficients under the conditions adopted in the MC experiment.
3. At least for the set of parameter values that we've considered, the OLS coefficient estimator seems have a sampling distribution that is Normal, even when the sample size, n, is very small.
If we were to repeat this experiment with different true values for the parameters in the DGP, we'd keep coming to the same conclusion. This might lead us to suspect (correctly in this case) that these properties of the OLS estimator apply for any values of the parameters.
That, in turn, might motivate us to try and establish this result with a formal mathematical proof. In fact, this "inter-play" between simulation experiments and formal mathematical derivations is an important way of establishing new theoretical results in econometrics.
Now let's move to the second part of this post, where we'll look at a simple MC experiment that will demonstrate the fact that when we have a (time-series) regression model that has a lagged value of the dependent variable, y, included as a regressor, the OLS estimator for the coefficient vector is biased if the sample size is finite.
In this case, the simple "dynamic" model that will form our DGP is:
yt = α + β yt-1 + ut ; t = 1, 2, 3, ......, n. (2)
The random values of u are pair-wise uncorrelated, and come from a Normal distribution with a mean of zero, and a (positive, finite) variance of σ2.
From the discussion above, you can easily see what steps are followed in each replication of the MC experiment. One important thing to notice in this case, however, is that the (non-constant) regressor in the model is no longer "fixed in repeated samples". Each time that we generate a new sample of yt values, we'll also have a new sample of yt-1 values. So, in this case we have a regressor that is non-random. (However, it's not correlated with the error term, because we're explicitly forcing the latter to take values that are independent over time (i.e., serially independent).)
Figures 3 to 7 illustrate some of the results from our experiment. The OLS estimators for both α and β are in fact biased, but to conserve space we demonstrate this just for β. The OLS estimator for this parameter is labelled "b". Our MC experiment is again based on N = 5,000 replications. The sample sizes that have been considered are n = 10, 30, 100, 500, and 3,000. The values that were assigned to α, β, and σ in the DGP were 1.0, 0.5, and 1.0 respectively.





Our third experiment investigates some of the properties of lease squares when it is applied to a model that is non-linear in the parameters. You may know already that, in general, the non-linear least squares (NLLS) estimator is biased, although weakly consistent under standard conditions. Let's see if we can illustrate this.
In this case we'll consider the following regression model:
yi = α + βxiγ+ ei ; i = 1, 2, 3, ..., n (3)
Once again, the values of x will be "fixed in repeated samples" (so the same values will be used, for a given value of n, in each replication of the MC experiment). The error term, e, takes values that are drawn independently from an N[0 , σ2] distribution. I have fixed the values of the parameters to α = 1.0, β = 1.0, γ = 3.0, and σ = 1.0 throughout the experiment.
The MC results for n = 10, 25, and 100 appear in Figures 8 to 10 below.



Once again, the fact that the standard deviation of the sampling distribution of b declines as the sample size increases is a reflection of the weak consistency of the NLLS estimator. Finally, we can see that even though the error term in the model is Normally distributed, the sampling distribution of the NLLS estimator of beta is non-Normal for small samples. However, this distribution is asymptotically Normal. (Look at the skewness and kurtosis coefficients in Figures 8 to 10, and the associated Jarqe-Bera test statistics.)
Hopefully, the three regression examples that I've considered in this post will provide a good idea of how we can explore just a few of the (sampling) properties of some familiar estimators by using Monte Carlo simulation.
There's lots more that we can do, and I'll provide some further examples relating to both estimation and hypothesis testing in some upcoming posts on this general topic.
Could you provided instances where simulations led to formal proofs regarding the properties of estimators or test statistics?
ReplyDeleteIn the 1970's this helped with establishing formal proofs of the small-sample properties of various simultaneous equations estimators.
DeleteDear Prof. Giles,
ReplyDeleteThank you for these posts about using Monte Carlo simulation to illustrate properties of the sampling distribution of OLS parameters. I have a question about the necessity of keeping the observed values of the regressors, x2 and x3, as non-random. How necessary is it to keep these regressors "fixed in repeated samples"?
Absolutely essential for this exercise. Unless you want to see the bias introduced into the OLS estimator when you have random regressors.
DeleteThanks for the reply. I just want to clarify one additional question I have: In econometrics, the assumption of non-stochastic regressors is often relaxed. Thus, the vector of regressors may be viewed as either all stochastic or a mixture of stochastic and non-stochastic regressors. I performed a simple simulation with the following data generating process:
Deletey = \beta_0 + \beta_1 x + \epsilon,
where \beta_0 = 1, \beta_1 = 0.5, and x and \epsilon are normally distributed with mean 0 and variance 1. I draw a sample of 500 observation on x and \epsilon, compute y, and estimate the OLS regression coefficients. I then repeat this exercise 1,000 times and collect the results---there is no assumption of x being fixed in repeated samples. OLS, on average, still demonstrates that the parameter estimate for \beta_1 is unbiased. May I take this to assume that I have demonstrated conditional unbiasedness? Then one could argue that I could integrate over the conditional distribution to demonstrate unconditional bias. Does this line of thought hold? I want to think how this finding connects with the idea you have suggested above, which suggests that using stochastic regressors will allow me to see bias introduced into the OLS estimator. Thank you again for your insightful blog and comments.
Chris - if the random regressors are uncorrelated with the errors, then of course there is no bias. Does that make sense?
DeleteDavid
Yes, everything makes perfect sense now. When doing these simulations, I did not fully appreciate the importance of having fixed regressors because I would usually select a large n. For example, I often set my n=500 (sample size) and N=5,000 (number of replications). Thus, in many cases, I would not reject normality of the sampling distribution; however, as you clearly point out (using the dynamic OLS model as an example), with smaller sample sizes, the distribution of OLS estimates are not normally distributed.
DeleteWhen I set n=10 and N=5,000, I did one simulation where I drew x from a normal(0,1) each time I drew the error term, and I was able to reject normality of the 5,000 OLS coefficient estimates very easily; the p-values were extremely small using a test similar to the Jarque-Bera test. I then did another simulation where I drew x once and kept it fixed across all the replications; I could no longer reject normality. The p-value was close to 0.56.
Thus, I can clearly see the important of keeping x as a fixed regressor when trying to do simulations where one is interested in computing empirical power, for example. Thanks again!
My pleasure - thanks for the helpful discussion.
DeleteDG